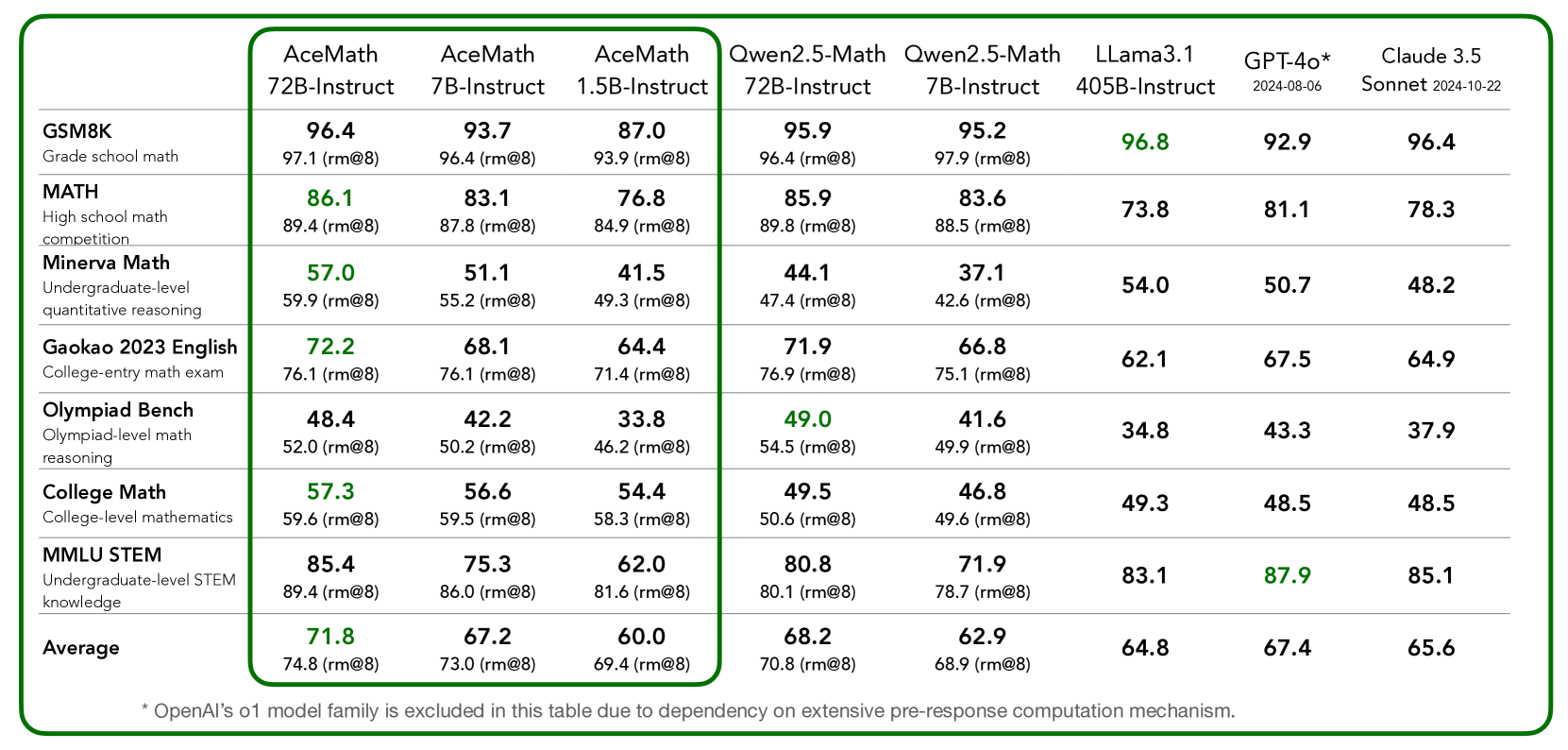
## Table: AI Model Performance Comparison Across Math and STEM Benchmarks
### Overview
This table compares the performance of multiple AI models (AceMath, Qwen, LLama, GPT-4o, Claude 3.5 Sonnet) across 8 math/STEM benchmarks, including grade school math, high school math competitions, undergraduate-level reasoning, college-entry exams, Olympiad-level problems, college mathematics, and STEM knowledge. Scores are presented as percentages with "rm@8" values in parentheses, indicating performance relative to a reference model.
---
### Components/Axes
- **Rows (Benchmarks)**:
1. GSM8K (Grade school math)
2. MATH (High school math competition)
3. Minerva Math (Undergraduate-level quantitative reasoning)
4. Gaokao 2023 English (College-entry math exam)
5. Olympiad Bench (Olympiad-level math reasoning)
6. College Math (College-level mathematics)
7. MMLU STEM (Undergraduate-level STEM knowledge)
8. Average (Overall performance)
- **Columns (Models/Versions)**:
- AceMath 72B-Instruct
- AceMath 7B-Instruct
- AceMath 1.5B-Instruct
- Qwen2.5-Math 72B-Instruct
- Qwen2.5-Math 7B-Instruct
- LLama3.1 405B-Instruct
- GPT-4o* (2024-08-06)
- Claude 3.5 Sonnet (2024-10-22)
- **Footnote**:
* OpenAI’s o1 model family excluded due to dependency on extensive pre-response computation mechanisms.
---
### Detailed Analysis
#### Benchmark Performance
1. **GSM8K (Grade school math)**:
- GPT-4o: 92.9 (highest)
- Claude 3.5 Sonnet: 96.4 (highest)
- AceMath 72B-Instruct: 96.4 (highest among non-OpenAI models)
2. **MATH (High school math competition)**:
- Qwen2.5-Math 72B-Instruct: 89.8 (highest)
- Claude 3.5 Sonnet: 78.3 (lowest among top models)
3. **Minerva Math (Undergraduate reasoning)**:
- LLama3.1 405B-Instruct: 54.0 (highest)
- AceMath 7B-Instruct: 51.1 (lowest)
4. **Gaokao 2023 English**:
- Qwen2.5-Math 72B-Instruct: 76.9 (highest)
- LLama3.1 405B-Instruct: 62.1 (lowest)
5. **Olympiad Bench (Advanced reasoning)**:
- Qwen2.5-Math 72B-Instruct: 54.5 (highest)
- LLama3.1 405B-Instruct: 34.8 (lowest)
6. **College Math**:
- GPT-4o: 48.5 (highest)
- LLama3.1 405B-Instruct: 49.3 (lowest)
7. **MMLU STEM**:
- GPT-4o: 87.9 (highest)
- LLama3.1 405B-Instruct: 83.1 (lowest)
8. **Average**:
- GPT-4o: 67.4
- Claude 3.5 Sonnet: 65.6
- LLama3.1 405B-Instruct: 64.8
---
### Key Observations
1. **Model Strengths**:
- **GPT-4o** excels in MMLU STEM (87.9) and GSM8K (92.9), suggesting strong foundational and STEM knowledge.
- **Claude 3.5 Sonnet** leads in GSM8K (96.4) but underperforms in Olympiad Bench (37.9).
- **Qwen2.5-Math 72B-Instruct** dominates in Olympiad Bench (54.5) and MATH (89.8).
2. **Weaknesses**:
- **Olympiad Bench** scores are consistently low across all models (33.8–54.5), indicating a gap in advanced problem-solving.
- **LLama3.1 405B-Instruct** struggles in Minerva Math (54.0) and Gaokao (62.1) despite its large parameter size.
3. **Trends**:
- Larger models (e.g., 72B-Instruct, 405B-Instruct) generally outperform smaller ones in most benchmarks.
- OpenAI’s o1 exclusion suggests computational constraints may limit its inclusion in direct comparisons.
---
### Interpretation
The table highlights trade-offs between model size, training focus, and performance across math/STEM domains. GPT-4o and Claude 3.5 Sonnet demonstrate superior general math proficiency, while Qwen2.5-Math 72B-Instruct specializes in advanced reasoning (Olympiad Bench). The exclusion of OpenAI’s o1 model underscores the computational trade-offs in real-time reasoning tasks. Notably, Olympiad-level performance remains a universal challenge, suggesting limitations in current AI models’ ability to handle highly abstract or novel problems. The "rm@8" values indicate relative performance, with higher values reflecting stronger alignment with reference models.