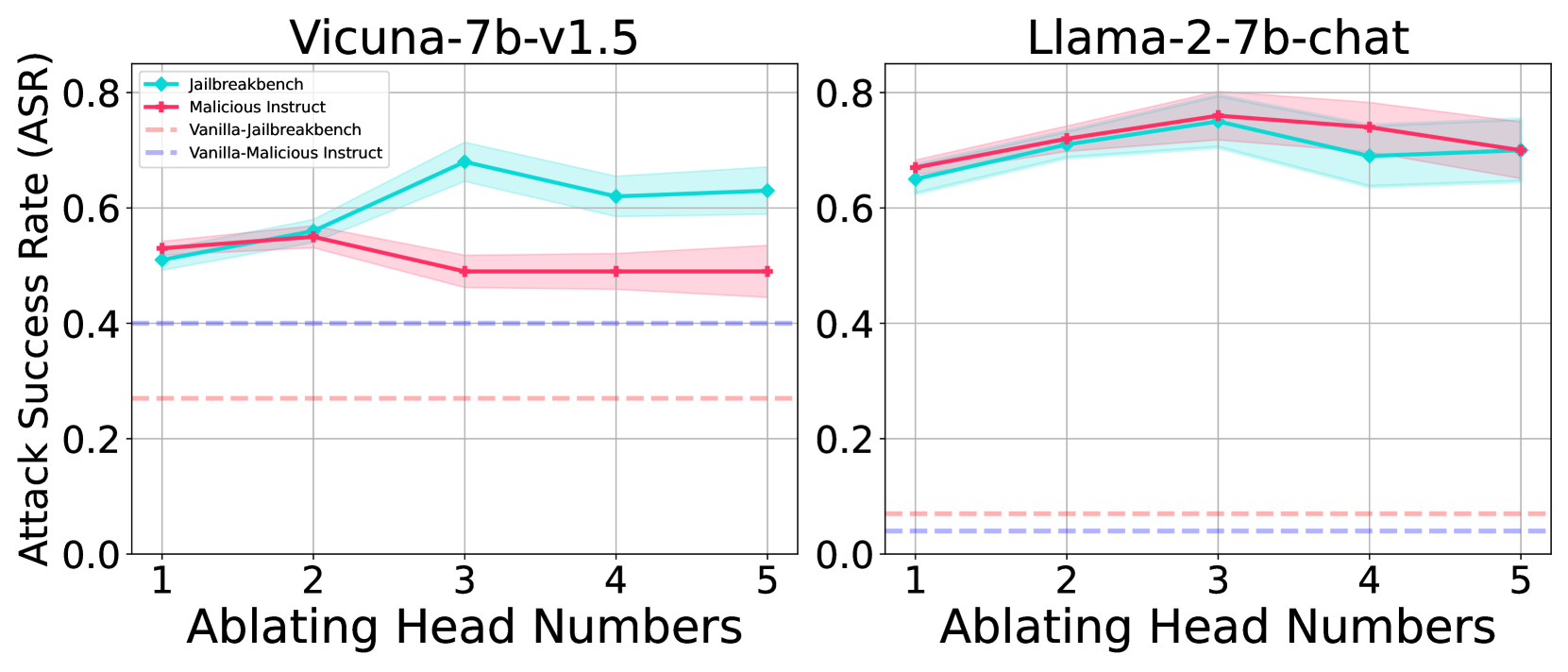
## Line Chart: Attack Success Rate vs. Ablating Head Numbers for Two Language Models
### Overview
The image presents two line charts comparing the attack success rate (ASR) against the number of ablating head numbers for two language models: Vicuna-7b-v1.5 and Llama-2-7b-chat. Each chart displays four data series representing different attack scenarios: "Jailbreakbench," "Malicious Instruct," "Vanilla-Jailbreakbench," and "Vanilla-Malicious Instruct." The charts aim to illustrate how the ASR changes as head numbers are ablated (removed) for each model under different attack conditions.
### Components/Axes
* **X-axis (Horizontal):** "Ablating Head Numbers," with values ranging from 1 to 5.
* **Y-axis (Vertical):** "Attack Success Rate (ASR)," ranging from 0.0 to 0.8.
* **Chart Titles:** "Vicuna-7b-v1.5" (left chart) and "Llama-2-7b-chat" (right chart).
* **Legend (Top-Left of Left Chart):**
* **Cyan:** "Jailbreakbench"
* **Red:** "Malicious Instruct"
* **Light Red (dashed):** "Vanilla-Jailbreakbench"
* **Light Purple (dashed):** "Vanilla-Malicious Instruct"
### Detailed Analysis
**Left Chart: Vicuna-7b-v1.5**
* **Jailbreakbench (Cyan):** The line starts at approximately 0.52 at head number 1, increases to approximately 0.55 at head number 2, peaks at approximately 0.70 at head number 3, then decreases to approximately 0.62 at head number 4 and remains at approximately 0.63 at head number 5.
* **Malicious Instruct (Red):** The line starts at approximately 0.53 at head number 1, increases to approximately 0.55 at head number 2, decreases to approximately 0.49 at head number 3, remains at approximately 0.48 at head number 4 and remains at approximately 0.46 at head number 5.
* **Vanilla-Jailbreakbench (Light Red, Dashed):** The line remains constant at approximately 0.27 across all head numbers.
* **Vanilla-Malicious Instruct (Light Purple, Dashed):** The line remains constant at approximately 0.40 across all head numbers.
**Right Chart: Llama-2-7b-chat**
* **Jailbreakbench (Cyan):** The line starts at approximately 0.65 at head number 1, increases to approximately 0.72 at head number 2, peaks at approximately 0.77 at head number 3, then decreases to approximately 0.71 at head number 4 and remains at approximately 0.70 at head number 5.
* **Malicious Instruct (Red):** The line starts at approximately 0.67 at head number 1, increases to approximately 0.74 at head number 2, peaks at approximately 0.79 at head number 3, then decreases to approximately 0.73 at head number 4 and remains at approximately 0.72 at head number 5.
* **Vanilla-Jailbreakbench (Light Red, Dashed):** The line remains constant at approximately 0.07 across all head numbers.
* **Vanilla-Malicious Instruct (Light Purple, Dashed):** The line remains constant at approximately 0.04 across all head numbers.
### Key Observations
* For both models, the "Vanilla-Jailbreakbench" and "Vanilla-Malicious Instruct" attack success rates remain relatively constant regardless of the number of ablating head numbers.
* For Vicuna-7b-v1.5, "Jailbreakbench" shows a peak at head number 3, while "Malicious Instruct" decreases after head number 2.
* For Llama-2-7b-chat, both "Jailbreakbench" and "Malicious Instruct" peak at head number 3 and then slightly decrease.
* Llama-2-7b-chat generally exhibits higher attack success rates for "Jailbreakbench" and "Malicious Instruct" compared to Vicuna-7b-v1.5.
* The shaded regions around the "Jailbreakbench" and "Malicious Instruct" lines indicate the uncertainty or variance in the ASR.
### Interpretation
The data suggests that ablating head numbers has a varying impact on the attack success rates of the two language models, depending on the attack scenario. The "Vanilla" attacks (Jailbreakbench and Malicious Instruct) are largely unaffected by head ablation, indicating a baseline level of vulnerability. The "Jailbreakbench" and "Malicious Instruct" attacks show more sensitivity to head ablation, with a peak in ASR around head number 3 for both models, suggesting that specific heads might be more critical for these types of attacks. Llama-2-7b-chat appears to be more vulnerable to these attacks overall, as indicated by its higher ASR values compared to Vicuna-7b-v1.5. The trends observed can help in understanding the models' vulnerabilities and developing strategies to improve their robustness against adversarial attacks.