\n
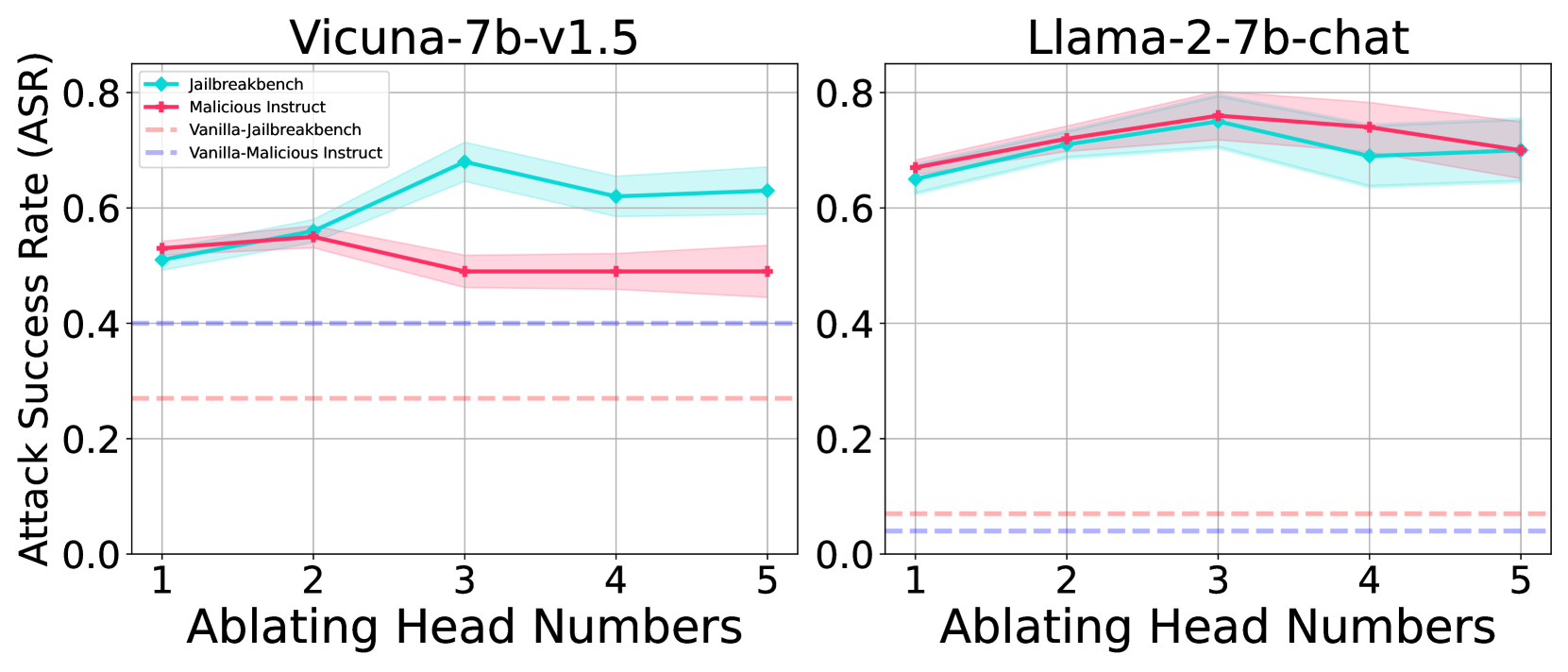
## Line Chart: Attack Success Rate vs. Ablating Head Numbers
### Overview
The image presents two line charts comparing the Attack Success Rate (ASR) for two language models, Vicuna-7b-v1.5 and Llama-2-7b-chat, as head numbers are ablated (removed). Each chart displays two data series, representing different attack prompts: "jailbreakbench" and "Malicious Instruct", with both "Vanilla" and "jailbreakbench" variations. The charts aim to illustrate how removing heads from the models affects their vulnerability to these attacks.
### Components/Axes
* **X-axis:** "Ablating Head Numbers" - Scale from 1 to 5, representing the number of heads removed.
* **Y-axis:** "Attack Success Rate (ASR)" - Scale from 0.0 to 0.8.
* **Left Chart Title:** "Vicuna-7b-v1.5"
* **Right Chart Title:** "Llama-2-7b-chat"
* **Legend (Top-Left of each chart):**
* Red Line: "jailbreakbench"
* Light Red Dashed Line: "Malicious Instruct"
* Cyan Line: "Vanilla-jailbreakbench"
* Light Cyan Dashed Line: "Vanilla-Malicious Instruct"
* **Gridlines:** Present on both charts, aiding in value estimation.
### Detailed Analysis or Content Details
**Vicuna-7b-v1.5 (Left Chart):**
* **jailbreakbench (Red Line):** Starts at approximately 0.53, increases to a peak of around 0.66 at head number 4, then decreases slightly to approximately 0.62 at head number 5.
* **Malicious Instruct (Light Red Dashed Line):** Starts at approximately 0.51, remains relatively stable around 0.52-0.54 between head numbers 1 and 3, then increases to approximately 0.58 at head number 4, and decreases to approximately 0.55 at head number 5.
* **Vanilla-jailbreakbench (Cyan Line):** Starts at approximately 0.33, increases to approximately 0.42 at head number 2, then increases to approximately 0.52 at head number 3, then decreases to approximately 0.48 at head number 4, and finally decreases to approximately 0.45 at head number 5.
* **Vanilla-Malicious Instruct (Light Cyan Dashed Line):** Remains consistently low, fluctuating between approximately 0.28 and 0.33 across all head numbers.
**Llama-2-7b-chat (Right Chart):**
* **jailbreakbench (Red Line):** Starts at approximately 0.74, decreases to approximately 0.70 at head number 2, then increases to approximately 0.76 at head number 3, then decreases to approximately 0.72 at head number 4, and finally decreases to approximately 0.70 at head number 5.
* **Malicious Instruct (Light Red Dashed Line):** Remains consistently low, fluctuating between approximately 0.28 and 0.32 across all head numbers.
* **Vanilla-jailbreakbench (Cyan Line):** Starts at approximately 0.64, increases to approximately 0.68 at head number 2, then decreases to approximately 0.66 at head number 3, then decreases to approximately 0.64 at head number 4, and finally decreases to approximately 0.62 at head number 5.
* **Vanilla-Malicious Instruct (Light Cyan Dashed Line):** Remains consistently low, fluctuating between approximately 0.25 and 0.28 across all head numbers.
### Key Observations
* **Vicuna-7b-v1.5:** The "jailbreakbench" attack has a significantly higher success rate than the "Malicious Instruct" attack, and the "Vanilla" variations consistently show lower success rates. Ablating heads initially increases the success rate of "jailbreakbench" before decreasing it slightly.
* **Llama-2-7b-chat:** The "jailbreakbench" attack also has a higher success rate, but the effect of ablating heads is less pronounced. The "Malicious Instruct" and "Vanilla" variations remain consistently low.
* **Vanilla Attacks:** The "Vanilla" attacks consistently have a much lower ASR than the non-Vanilla attacks for both models.
* **Llama-2-7b-chat is more robust:** The ASR for Llama-2-7b-chat is generally higher than Vicuna-7b-v1.5, but the ASR remains relatively stable across all head numbers.
### Interpretation
The data suggests that ablating heads can influence the vulnerability of language models to jailbreaking attacks, but the effect varies depending on the model and the attack prompt. The higher success rate of "jailbreakbench" attacks compared to "Malicious Instruct" attacks indicates that the models are more susceptible to prompts designed to bypass safety mechanisms through specific jailbreaking techniques. The consistently low success rates of the "Vanilla" attacks suggest that the models' inherent safety features are effective against simpler, non-crafted attacks.
The difference in behavior between Vicuna-7b-v1.5 and Llama-2-7b-chat suggests that their architectures and training data lead to different vulnerabilities. The relative stability of Llama-2-7b-chat's ASR across head ablations could indicate a more distributed safety mechanism, while Vicuna-7b-v1.5's fluctuating ASR suggests that certain heads play a more critical role in resisting attacks.
The observed trends highlight the importance of understanding how model architecture and training influence vulnerability to adversarial attacks. Further investigation could explore the specific roles of the ablated heads and identify strategies for mitigating these vulnerabilities.