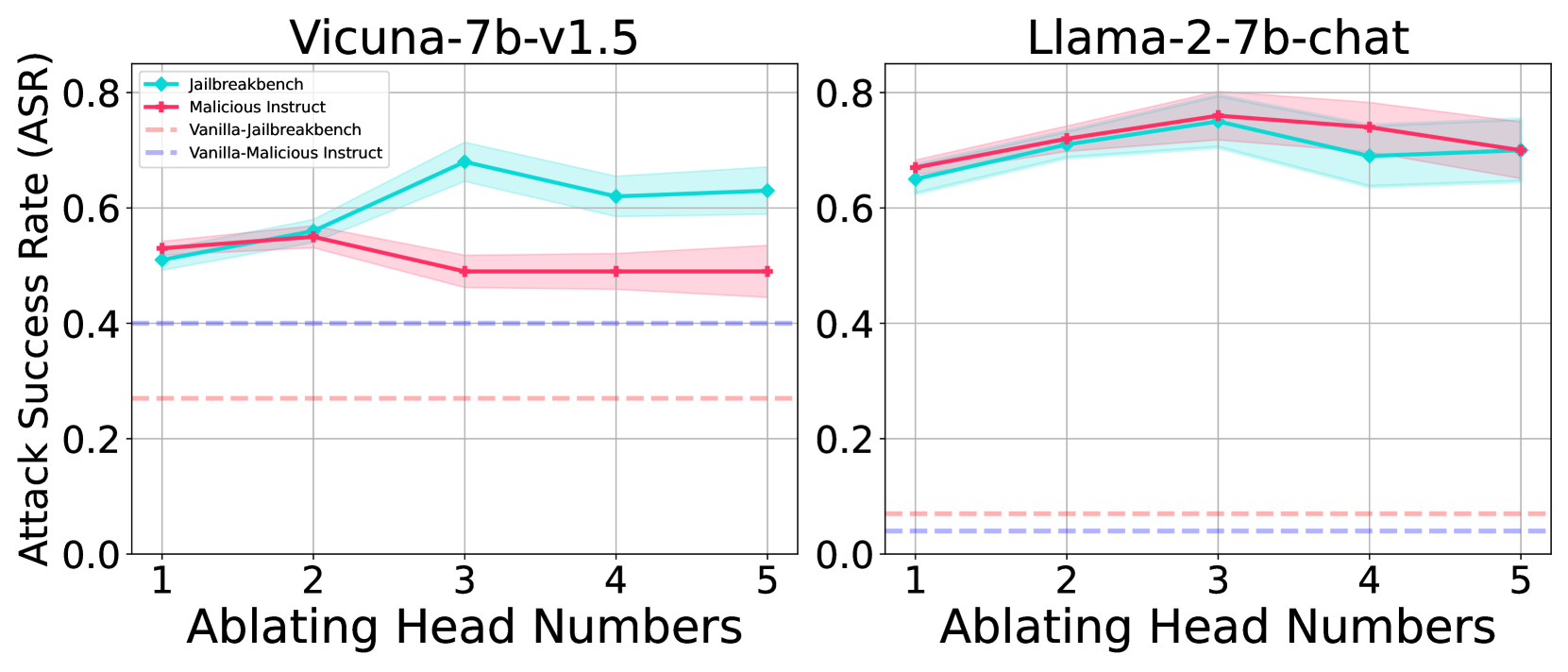
## Line Graphs: Attack Success Rate (ASR) vs. Ablating Head Numbers for Vicuna-7b-v1.5 and Llama-2-7b-chat
### Overview
The image contains two side-by-side line graphs comparing attack success rates (ASR) across different ablated head numbers (1–5) for two language models: **Vicuna-7b-v1.5** (left) and **Llama-2-7b-chat** (right). Three attack methods are analyzed: **Jailbreakbench** (cyan), **Malicious Instruct** (red), and **Vanilla-Malicious Instruct** (purple). Shaded regions represent confidence intervals.
---
### Components/Axes
- **X-axis**: Ablating Head Numbers (1–5, integer steps).
- **Y-axis**: Attack Success Rate (ASR) from 0.0 to 0.8.
- **Legends**:
- **Left Graph (Vicuna-7b-v1.5)**: Legend in top-left corner.
- **Right Graph (Llama-2-7b-chat)**: Legend in top-right corner.
- **Lines**:
- **Jailbreakbench**: Cyan solid line with diamond markers.
- **Malicious Instruct**: Red solid line with square markers.
- **Vanilla-Malicious Instruct**: Purple dashed line with no markers.
---
### Detailed Analysis
#### Left Graph (Vicuna-7b-v1.5)
1. **Jailbreakbench (Cyan)**:
- Starts at ~0.52 (head 1), peaks at ~0.70 (head 3), then declines to ~0.63 (head 5).
- Confidence interval widens slightly at head 3.
2. **Malicious Instruct (Red)**:
- Starts at ~0.53 (head 1), peaks at ~0.55 (head 2), then declines to ~0.50 (head 5).
- Confidence interval narrows at head 2.
3. **Vanilla-Malicious Instruct (Purple)**:
- Flat line at ~0.40 across all heads.
#### Right Graph (Llama-2-7b-chat)
1. **Jailbreakbench (Cyan)**:
- Starts at ~0.65 (head 1), peaks at ~0.75 (head 3), then declines to ~0.70 (head 5).
- Confidence interval widens at head 3.
2. **Malicious Instruct (Red)**:
- Starts at ~0.70 (head 1), peaks at ~0.75 (head 3), then declines to ~0.72 (head 5).
- Confidence interval narrows at head 3.
3. **Vanilla-Malicious Instruct (Purple)**:
- Flat line at ~0.05 across all heads.
---
### Key Observations
1. **Jailbreakbench Dominates**:
- Both models show Jailbreakbench achieving the highest ASR, with Llama-2-7b-chat consistently outperforming Vicuna-7b-v1.5.
2. **Malicious Instruct vs. Vanilla-Malicious Instruct**:
- Malicious Instruct outperforms Vanilla-Malicious Instruct in both models, but the gap is smaller in Llama-2-7b-chat.
3. **Ablation Impact**:
- ASR peaks at head 3 for both models, suggesting critical vulnerability in this head.
4. **Vanilla-Malicious Instruct Underperformance**:
- Particularly weak in Llama-2-7b-chat (ASR ~0.05), indicating potential flaws in its design.
---
### Interpretation
- **Model Vulnerability**: Llama-2-7b-chat exhibits higher ASR across all attack methods, suggesting it is more susceptible to jailbreaking than Vicuna-7b-v1.5.
- **Head-Specific Weakness**: The peak at head 3 implies this attention head is critical for resisting attacks. Ablating it significantly reduces model robustness.
- **Attack Method Efficacy**:
- Jailbreakbench is the most effective attack, leveraging structural vulnerabilities.
- Malicious Instruct’s performance gap over Vanilla