TECHNICAL ASSET FINGERPRINT
54fa1586608e89d3ab4aae65
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
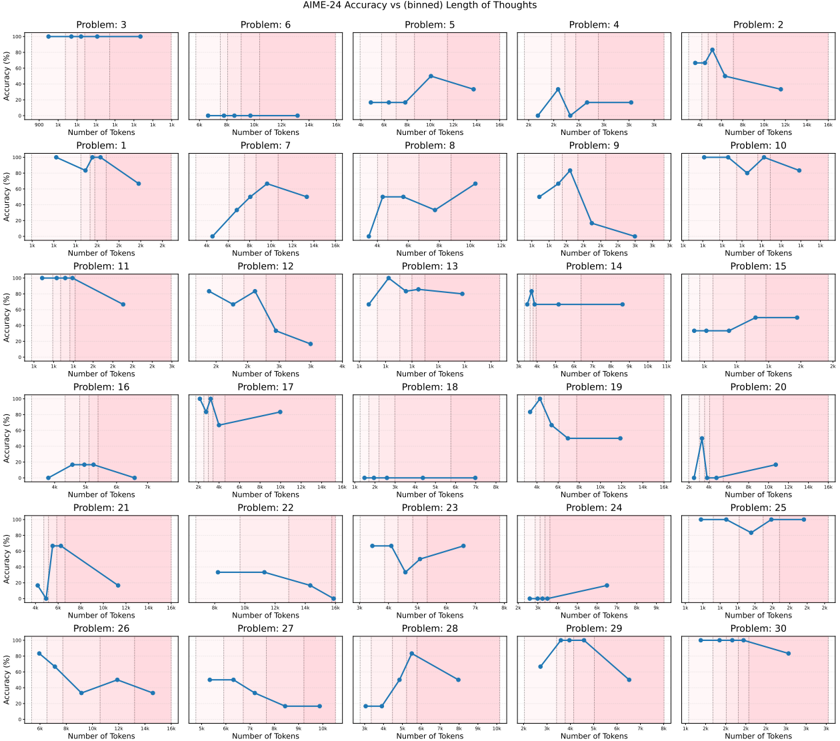
## Chart Type: Multiple Line Charts
### Overview
The image presents a grid of 30 small line charts, each displaying "Accuracy (%)" versus "Number of Tokens" for a different problem labeled "Problem: [Number]". The x-axis (Number of Tokens) and y-axis (Accuracy (%)) scales vary slightly across the charts. Each chart has a light pink background.
### Components/Axes
* **Title:** AIME-24 Accuracy vs (binned) Length of Thoughts
* **X-axis:** Number of Tokens. The scale varies across charts, ranging from 0 to a maximum of 3k, 7k, 8k, 12k, or 16k.
* **Y-axis:** Accuracy (%). The scale is consistent across all charts, ranging from 0% to 100%.
* **Chart Titles:** Each chart is labeled "Problem: [Number]", where the number ranges from 1 to 30.
* **Background:** Light pink background on each chart.
* **Vertical Dashed Lines:** Each chart has 2-3 vertical dashed lines, likely indicating bin boundaries.
### Detailed Analysis
Here's a breakdown of each chart, noting the general trend and approximate data points:
**Row 1:**
* **Problem: 3:** Accuracy is consistently high (near 100%) across the range of tokens (900 to 16k).
* **Problem: 6:** Accuracy is very low (near 0%) across the range of tokens (0 to 16k).
* **Problem: 5:** Accuracy starts low (around 15% at 4k tokens), increases to approximately 50% at 10k tokens, and then decreases slightly to around 40% at 16k tokens.
* **Problem: 4:** Accuracy starts low (near 0% at 2k tokens), peaks around 40% at 3k tokens, then decreases and plateaus around 20% from 4k to 16k tokens.
* **Problem: 2:** Accuracy starts around 20% at 4k tokens, increases sharply to around 80% at 6k tokens, and then decreases to around 60% at 8k tokens.
**Row 2:**
* **Problem: 1:** Accuracy starts high (near 90% at 1k tokens), dips to around 80% at 1.5k tokens, and then rises back to 90% at 2k tokens.
* **Problem: 7:** Accuracy increases steadily from near 0% at 4k tokens to around 70% at 12k tokens, then decreases slightly to around 60% at 16k tokens.
* **Problem: 8:** Accuracy starts around 50% at 4k tokens, increases to around 70% at 8k tokens, and then decreases slightly to around 60% at 12k tokens.
* **Problem: 9:** Accuracy peaks around 80% at 2k tokens, then decreases to near 0% at 3k tokens.
* **Problem: 10:** Accuracy is generally high, fluctuating between 80% and 100% across the range of tokens (4k to 16k).
**Row 3:**
* **Problem: 11:** Accuracy starts high (near 100% at 1k tokens) and decreases to around 60% at 3k tokens.
* **Problem: 12:** Accuracy starts around 80% at 2k tokens, dips to around 60% at 2.5k tokens, and then decreases to around 20% at 3k tokens.
* **Problem: 13:** Accuracy peaks around 90% at 1k tokens, then decreases and plateaus around 70% from 1.5k to 2k tokens.
* **Problem: 14:** Accuracy is consistently low (near 0%) until 3k tokens, then jumps to around 80% at 3.5k tokens, and remains constant.
* **Problem: 15:** Accuracy is consistently low (near 0%) until 1k tokens, then increases to around 20% at 1.5k tokens, and then increases to around 30% at 2k tokens.
**Row 4:**
* **Problem: 16:** Accuracy starts low (near 0%) and increases to around 20% at 5k tokens, then decreases to near 0% at 7k tokens.
* **Problem: 17:** Accuracy starts low (near 0%) until 2k tokens, then jumps to around 90% at 3k tokens, and then decreases to around 70% at 6k tokens.
* **Problem: 18:** Accuracy is consistently very low (near 0%) across the range of tokens (1k to 7k).
* **Problem: 19:** Accuracy peaks around 80% at 3k tokens, then decreases to around 20% at 12k tokens.
* **Problem: 20:** Accuracy starts low (near 0%) until 4k tokens, then jumps to around 20% at 4.5k tokens, and then increases to around 30% at 6k tokens.
**Row 5:**
* **Problem: 21:** Accuracy peaks around 70% at 4k tokens, then decreases to around 20% at 16k tokens.
* **Problem: 22:** Accuracy starts around 50% at 4k tokens, and decreases to around 20% at 16k tokens.
* **Problem: 23:** Accuracy starts around 80% at 3k tokens, dips to around 40% at 4k tokens, and then increases to around 60% at 6k tokens.
* **Problem: 24:** Accuracy is consistently very low (near 0%) until 4k tokens, then increases to around 10% at 6k tokens.
* **Problem: 25:** Accuracy is consistently high (near 100%) across the range of tokens (4k to 16k).
**Row 6:**
* **Problem: 26:** Accuracy starts high (around 80% at 6k tokens), and decreases to around 20% at 16k tokens.
* **Problem: 27:** Accuracy starts around 50% at 4k tokens, and decreases to around 20% at 10k tokens.
* **Problem: 28:** Accuracy peaks around 90% at 6k tokens, after starting near 0% at 3k tokens, then decreases to around 60% at 8k tokens.
* **Problem: 29:** Accuracy peaks around 80% at 4k tokens, then decreases to around 20% at 8k tokens.
* **Problem: 30:** Accuracy starts high (around 90% at 2k tokens), and decreases to around 40% at 3k tokens.
### Key Observations
* The accuracy varies significantly across different problems.
* For some problems, accuracy is consistently high or low regardless of the number of tokens.
* For other problems, accuracy fluctuates with the number of tokens, sometimes showing a peak or a decreasing trend.
* The x-axis scale (Number of Tokens) varies across the charts, which might be due to the nature of the problems or the binning strategy used.
### Interpretation
The charts illustrate how the accuracy of a model (likely a language model, given the context of "tokens") varies with the length of the input ("Length of Thoughts") for different problems within the AIME-24 dataset. The "binned" length suggests that the token counts have been grouped into ranges.
The variability in accuracy across problems indicates that some problems are inherently easier or more suitable for the model than others. The trends within each chart suggest that the optimal input length (in terms of tokens) can vary significantly depending on the specific problem. Some problems benefit from longer inputs (more tokens), while others perform better with shorter inputs. Some problems show no correlation between input length and accuracy.
The vertical dashed lines likely represent the boundaries of the bins used for grouping the token counts. These lines could be used to analyze the accuracy within specific token length ranges.
The data suggests that careful consideration of input length is crucial for optimizing model performance on the AIME-24 dataset, and that the optimal length may be problem-dependent. Further analysis could involve investigating the characteristics of the problems that exhibit different accuracy trends.
DECODING INTELLIGENCE...