\n
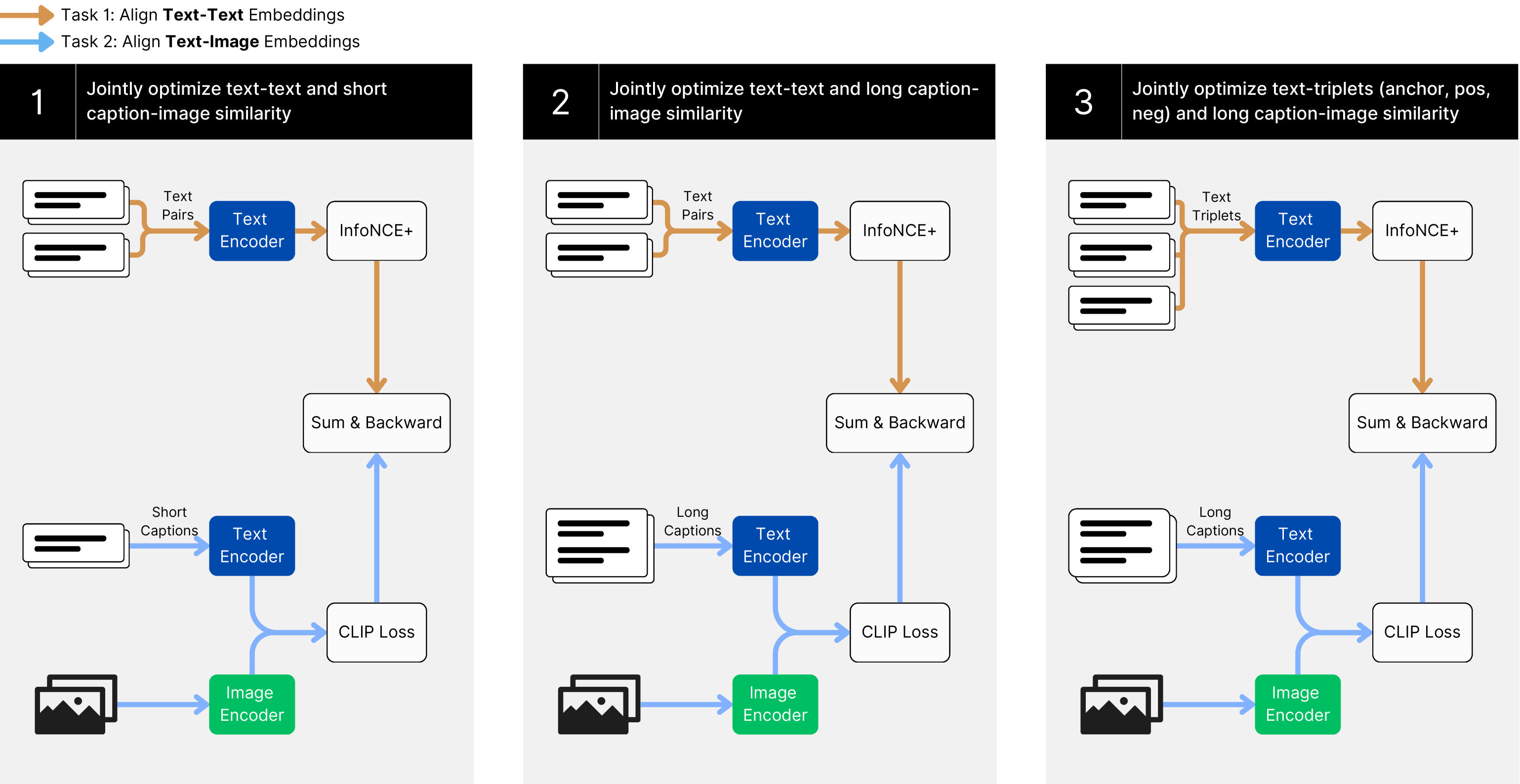
## Diagram: Multi-Task Alignment for Text and Image Embeddings
### Overview
This diagram illustrates a three-stage process for aligning text and image embeddings using a multi-task learning approach. Each stage builds upon the previous one, increasing the complexity of the text input and the optimization objective. The diagram depicts data flow through various encoders and loss functions, with backward propagation indicated by gray arrows.
### Components/Axes
The diagram is structured into three numbered stages (1, 2, 3) arranged horizontally. Each stage contains the following components:
* **Text Input:** Represented as lists of text (Text Pairs, Text Triplets).
* **Text Encoder:** A block labeled "Text Encoder" processes the text input.
* **Image Encoder:** A block labeled "Image Encoder" processes image input.
* **InfoNCE+:** A block labeled "InfoNCE+" receives output from the Text Encoder.
* **CLiP Loss:** A block labeled "CLiP Loss" receives output from the Image Encoder.
* **Sum & Backward:** A gray rectangular block indicating summation and backward propagation of gradients.
* **Arrows:** Indicate the flow of data and gradients.
* **Legend:** Two arrows at the top-left indicate:
* Orange arrow: Task 1 - Align Text-Text Embeddings
* Blue arrow: Task 2 - Align Text-Image Embeddings
### Detailed Analysis or Content Details
**Stage 1:**
* **Text Input:** "Text Pairs" (represented as a list of text strings).
* **Text Encoder:** Processes "Text Pairs".
* **InfoNCE+:** Receives output from the Text Encoder.
* **Short Captions:** "Short Captions" (represented as a list of text strings).
* **CLiP Loss:** Receives output from the Image Encoder.
* **Data Flow:** "Text Pairs" -> "Text Encoder" -> "InfoNCE+". "Short Captions" -> "Text Encoder" -> "CLiP Loss". Image input goes directly to "Image Encoder" -> "CLiP Loss".
* **Optimization:** Jointly optimizes text-text and short caption-image similarity.
**Stage 2:**
* **Text Input:** "Text Pairs" (represented as a list of text strings).
* **Text Encoder:** Processes "Text Pairs".
* **InfoNCE+:** Receives output from the Text Encoder.
* **Long Captions:** "Long Captions" (represented as a list of text strings).
* **CLiP Loss:** Receives output from the Image Encoder.
* **Data Flow:** "Text Pairs" -> "Text Encoder" -> "InfoNCE+". "Long Captions" -> "Text Encoder" -> "CLiP Loss". Image input goes directly to "Image Encoder" -> "CLiP Loss".
* **Optimization:** Jointly optimizes text-text and long caption-image similarity.
**Stage 3:**
* **Text Input:** "Text Triplets" (represented as a list of text strings).
* **Text Encoder:** Processes "Text Triplets".
* **InfoNCE+:** Receives output from the Text Encoder.
* **Long Captions:** "Long Captions" (represented as a list of text strings).
* **CLiP Loss:** Receives output from the Image Encoder.
* **Data Flow:** "Text Triplets" -> "Text Encoder" -> "InfoNCE+". "Long Captions" -> "Text Encoder" -> "CLiP Loss". Image input goes directly to "Image Encoder" -> "CLiP Loss".
* **Optimization:** Jointly optimizes text-triplets (anchor, pos, neg) and long caption-image similarity.
### Key Observations
* The complexity of the text input increases from "Text Pairs" to "Text Triplets" across the stages.
* The optimization objective expands from text-text and short caption-image similarity to include text-triplets and long caption-image similarity.
* The "InfoNCE+" component appears to be involved in the text-text alignment, while "CLiP Loss" handles the text-image alignment.
* The "Sum & Backward" blocks indicate that gradients are propagated back through the entire network for optimization.
### Interpretation
This diagram outlines a progressive training strategy for aligning text and image representations. By starting with simpler text inputs (pairs) and gradually increasing complexity (triplets), the model can learn more robust and nuanced relationships between text and images. The use of both InfoNCE+ and CLiP Loss suggests a combination of contrastive learning (InfoNCE+) for text alignment and a pre-trained vision-language model (CLiP) for image-text alignment. The orange and blue arrows indicate that the tasks are performed concurrently, suggesting a multi-task learning approach. The diagram demonstrates a sophisticated approach to learning joint embeddings, potentially improving performance on tasks such as image retrieval, captioning, and visual question answering. The use of triplets in the final stage likely aims to improve the model's ability to distinguish between relevant and irrelevant text-image pairs, enhancing the quality of the learned embeddings.