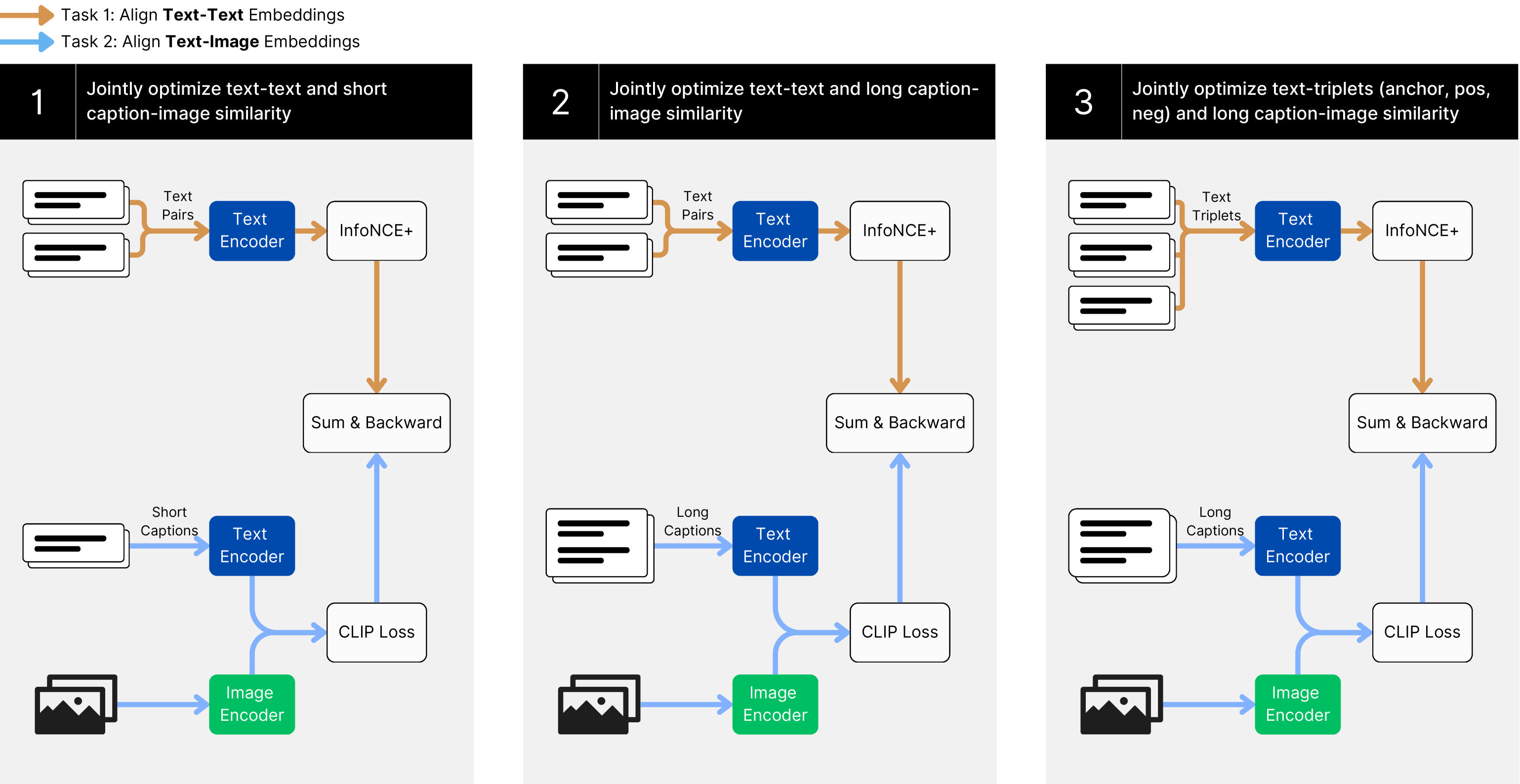
## Flowchart Diagram: Multi-Task Text-Image Alignment Framework
### Overview
The diagram illustrates a three-stage framework for optimizing text-image alignment through progressively complex tasks. Each task builds on the previous one, incorporating additional modalities (short/long captions, triplets) and optimization objectives. The flow uses color-coded components (orange for text pairs, blue for encoders, green for image encoder) connected by directional arrows.
### Components/Axes
1. **Task 1: Align Text-Text Embeddings**
- **Components**:
- Text Encoder (blue box)
- InfoNCE+ (white box)
- Sum & Backward (white box)
- Image Encoder (green box)
- **Flow**:
- Text Pairs → Text Encoder → InfoNCE+ → Sum & Backward
- Short Captions → Text Encoder → CLIP Loss
- Image Encoder connected to both Text Encoder and CLIP Loss
2. **Task 2: Align Text-Image Embeddings**
- **Components**:
- Text Encoder (blue box)
- InfoNCE+ (white box)
- Sum & Backward (white box)
- Image Encoder (green box)
- **Flow**:
- Text Pairs → Text Encoder → InfoNCE+ → Sum & Backward
- Long Captions → Text Encoder → CLIP Loss
- Image Encoder connected to Text Encoder and CLIP Loss
3. **Task 3: Align Text-Triplets and Long Captions**
- **Components**:
- Text Encoder (blue box)
- InfoNCE+ (white box)
- Sum & Backward (white box)
- Image Encoder (green box)
- **Flow**:
- Text Triplets → Text Encoder → InfoNCE+ → Sum & Backward
- Long Captions → Text Encoder → CLIP Loss
- Image Encoder connected to Text Encoder and CLIP Loss
### Detailed Analysis
- **Color Coding**:
- Orange arrows represent text pair/text triplet relationships
- Blue arrows indicate text encoder outputs
- Green arrows denote image encoder outputs
- Blue boxes represent text encoding components
- Green boxes represent image encoding components
- White boxes represent optimization modules (InfoNCE+, Sum & Backward, CLIP Loss)
- **Key Connections**:
- All tasks share the core Text Encoder and Image Encoder components
- Task 1 introduces basic text-image alignment via CLIP Loss
- Task 2 adds long caption processing while maintaining text-image alignment
- Task 3 introduces text triplet optimization (anchor/positive/negative) while preserving previous objectives
### Key Observations
1. **Progressive Complexity**: Each subsequent task adds new optimization objectives while retaining previous ones
2. **Shared Components**: The Text Encoder and Image Encoder are central to all tasks, suggesting reusable feature extraction
3. **Loss Functions**: CLIP Loss appears in all tasks but with different input modalities (short/long captions)
4. **Triplet Optimization**: Only Task 3 explicitly handles text triplet relationships for contrastive learning
### Interpretation
This framework demonstrates a hierarchical approach to text-image alignment:
1. **Foundation**: Task 1 establishes basic text-text alignment using InfoNCE loss
2. **Expansion**: Task 2 incorporates image alignment and long caption processing
3. **Refinement**: Task 3 introduces contrastive triplet learning for more nuanced representations
The architecture suggests a curriculum learning approach where each task builds on prior knowledge. The shared encoders imply transferable feature representations between modalities. The progressive addition of complexity (from text pairs to triplets) indicates an intentional design to handle increasingly challenging alignment scenarios. The use of InfoNCE+ across all tasks suggests it's the core contrastive learning objective, while CLIP Loss handles modality-specific alignment.