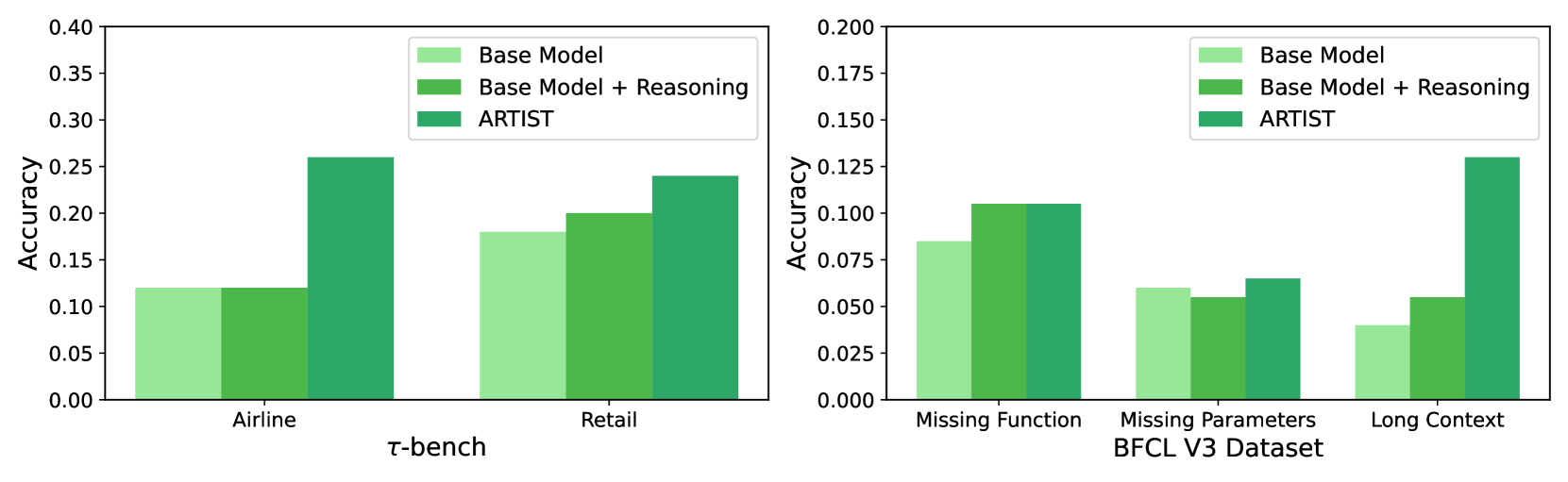
## Bar Chart: Model Accuracy Comparison
### Overview
The image presents two bar charts comparing the accuracy of three models: "Base Model", "Base Model + Reasoning", and "ARTIST". The left chart shows accuracy on the "τ-bench" dataset, specifically for "Airline" and "Retail" categories. The right chart shows accuracy on the "BFCL V3 Dataset" for "Missing Function", "Missing Parameters", and "Long Context" categories.
### Components/Axes
**Left Chart (τ-bench):**
* **X-axis:** "τ-bench" with categories "Airline" and "Retail".
* **Y-axis:** "Accuracy" ranging from 0.00 to 0.40, with increments of 0.05.
* **Legend (top-right):**
* Light Green: "Base Model"
* Medium Green: "Base Model + Reasoning"
* Dark Green: "ARTIST"
**Right Chart (BFCL V3 Dataset):**
* **X-axis:** "BFCL V3 Dataset" with categories "Missing Function", "Missing Parameters", and "Long Context".
* **Y-axis:** "Accuracy" ranging from 0.000 to 0.200, with increments of 0.025.
* **Legend (top-right):**
* Light Green: "Base Model"
* Medium Green: "Base Model + Reasoning"
* Dark Green: "ARTIST"
### Detailed Analysis
**Left Chart (τ-bench):**
* **Airline:**
* Base Model (Light Green): Accuracy ~0.12
* Base Model + Reasoning (Medium Green): Accuracy ~0.12
* ARTIST (Dark Green): Accuracy ~0.26
* **Retail:**
* Base Model (Light Green): Accuracy ~0.18
* Base Model + Reasoning (Medium Green): Accuracy ~0.20
* ARTIST (Dark Green): Accuracy ~0.24
**Right Chart (BFCL V3 Dataset):**
* **Missing Function:**
* Base Model (Light Green): Accuracy ~0.085
* Base Model + Reasoning (Medium Green): Accuracy ~0.105
* ARTIST (Dark Green): Accuracy ~0.105
* **Missing Parameters:**
* Base Model (Light Green): Accuracy ~0.06
* Base Model + Reasoning (Medium Green): Accuracy ~0.055
* ARTIST (Dark Green): Accuracy ~0.065
* **Long Context:**
* Base Model (Light Green): Accuracy ~0.04
* Base Model + Reasoning (Medium Green): Accuracy ~0.055
* ARTIST (Dark Green): Accuracy ~0.13
### Key Observations
* On the τ-bench dataset, the "ARTIST" model significantly outperforms the "Base Model" and "Base Model + Reasoning" for both "Airline" and "Retail" categories.
* On the BFCL V3 Dataset, the "ARTIST" model generally performs better than the other two models, especially for the "Long Context" category.
* The "Base Model" and "Base Model + Reasoning" models have similar performance on the τ-bench dataset, but the "Base Model + Reasoning" model shows slightly better performance for the "Retail" category.
* For the BFCL V3 Dataset, the "Base Model + Reasoning" model sometimes performs worse than the "Base Model" (e.g., "Missing Parameters").
### Interpretation
The charts suggest that the "ARTIST" model is more effective than the "Base Model" and "Base Model + Reasoning" models in the tested scenarios. The addition of reasoning to the base model does not consistently improve performance and can sometimes lead to a decrease in accuracy. The "ARTIST" model shows a significant advantage in handling "Long Context" scenarios within the BFCL V3 Dataset, indicating its potential for tasks requiring a broader understanding of the input. The τ-bench results show that ARTIST is significantly better at Airline and Retail tasks.