\n
## Bar Charts: Model Accuracy Comparison
### Overview
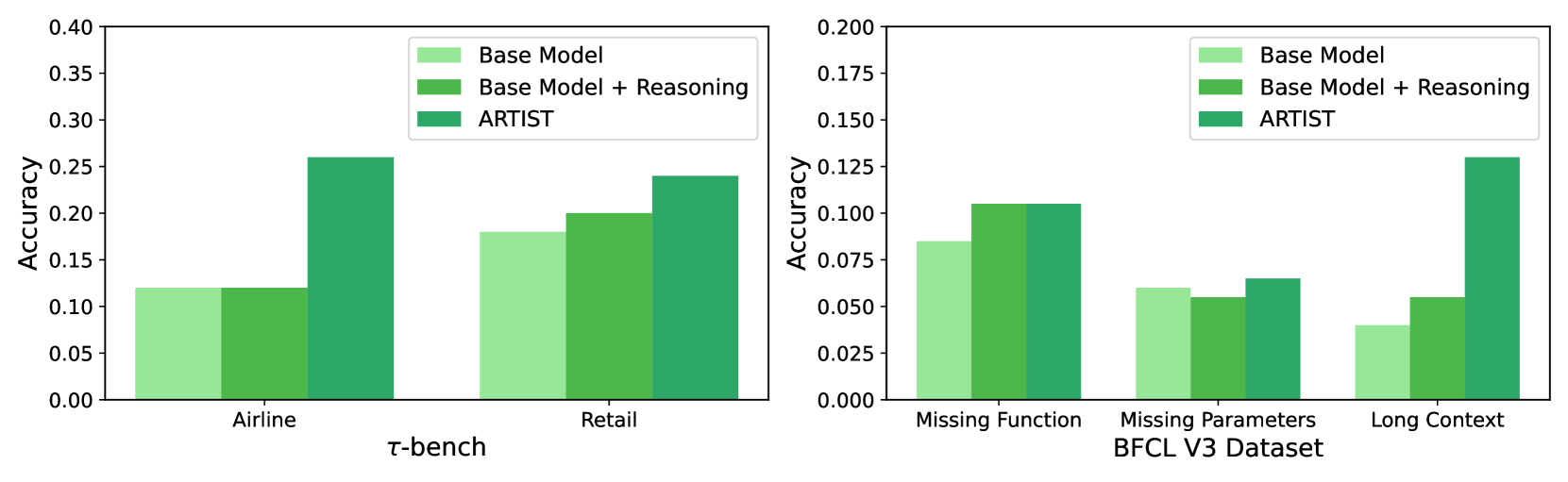
The image presents two bar charts comparing the accuracy of three models – "Base Model", "Base Model + Reasoning", and "ARTIST" – across different datasets. The first chart focuses on the datasets "Airline", "τ-bench", and "Retail". The second chart focuses on "Missing Function", "Missing Parameters BFCL V3 Dataset", and "Long Context". The y-axis represents accuracy, ranging from 0.00 to 0.40 in the first chart and 0.00 to 0.20 in the second chart.
### Components/Axes
* **X-axis (Chart 1):** Datasets - Airline, τ-bench, Retail
* **X-axis (Chart 2):** Datasets - Missing Function, Missing Parameters BFCL V3 Dataset, Long Context
* **Y-axis (Both Charts):** Accuracy (ranging from 0.00 to 0.40 for Chart 1 and 0.00 to 0.20 for Chart 2)
* **Legend (Both Charts):**
* Light Green: Base Model
* Medium Green: Base Model + Reasoning
* Dark Green: ARTIST
### Detailed Analysis or Content Details
**Chart 1: Airline, τ-bench, Retail**
* **Airline:**
* Base Model: Approximately 0.12
* Base Model + Reasoning: Approximately 0.18
* ARTIST: Approximately 0.26
* **τ-bench:**
* Base Model: Approximately 0.16
* Base Model + Reasoning: Approximately 0.22
* ARTIST: Approximately 0.28
* **Retail:**
* Base Model: Approximately 0.18
* Base Model + Reasoning: Approximately 0.22
* ARTIST: Approximately 0.25
**Chart 2: Missing Function, Missing Parameters BFCL V3 Dataset, Long Context**
* **Missing Function:**
* Base Model: Approximately 0.10
* Base Model + Reasoning: Approximately 0.11
* ARTIST: Approximately 0.13
* **Missing Parameters BFCL V3 Dataset:**
* Base Model: Approximately 0.05
* Base Model + Reasoning: Approximately 0.07
* ARTIST: Approximately 0.10
* **Long Context:**
* Base Model: Approximately 0.04
* Base Model + Reasoning: Approximately 0.08
* ARTIST: Approximately 0.13
### Key Observations
* ARTIST consistently outperforms both the Base Model and the Base Model + Reasoning across all datasets.
* The addition of reasoning to the Base Model consistently improves performance, but not to the level of ARTIST.
* The largest performance difference between the models appears on the "τ-bench" dataset in the first chart, and "Long Context" in the second chart.
* The performance gains from reasoning are more modest on the "Missing Function" dataset.
### Interpretation
The data suggests that the ARTIST model is significantly more effective than the Base Model and the Base Model + Reasoning across a variety of datasets. This indicates that ARTIST possesses capabilities that the other models lack, potentially related to its architecture or training data. The consistent improvement gained by adding reasoning to the Base Model suggests that reasoning is a valuable component for enhancing model performance, but it is not sufficient to match ARTIST's capabilities. The varying degree of improvement across datasets suggests that the effectiveness of reasoning may be dataset-dependent. The datasets themselves represent different challenges – from structured airline data to more complex reasoning tasks like missing function and long context. ARTIST's superior performance on these more challenging datasets highlights its ability to handle complex reasoning and contextual understanding. The data implies that ARTIST is a more robust and versatile model compared to the others.