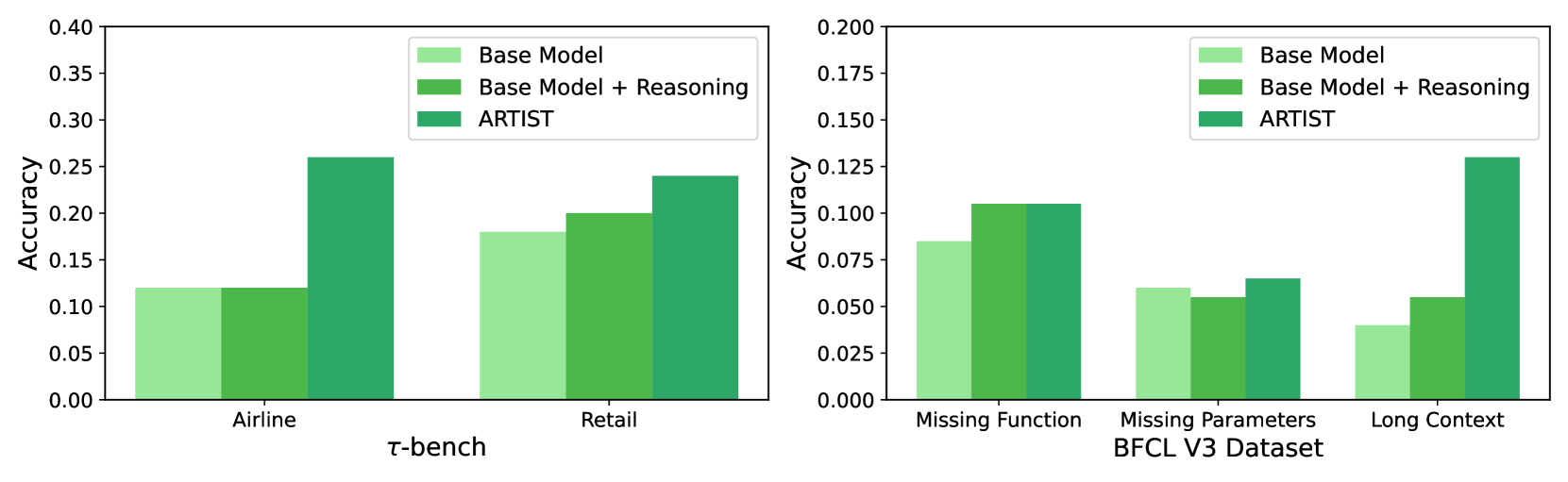
## Bar Chart: Model Accuracy Comparison Across Datasets
### Overview
The image contains two side-by-side bar charts comparing the accuracy of three machine learning models ("Base Model," "Base Model + Reasoning," and "ARTIST") across two datasets: τ-bench (left) and BFCL V3 Dataset (right). The charts use grouped bar clusters to visualize performance differences.
### Components/Axes
- **X-Axes**:
- Left Chart (τ-bench): Categories "Airline" and "Retail"
- Right Chart (BFCL V3 Dataset): Categories "Missing Function," "Missing Parameters," and "Long Context"
- **Y-Axes**:
- Both charts labeled "Accuracy" with scales from 0.00 to 0.40 (left) and 0.00 to 0.20 (right)
- **Legend**:
- Top-right corner of both charts, with color-coded labels:
- Light green: Base Model
- Dark green: Base Model + Reasoning
- Teal: ARTIST
- **Bar Colors**:
- All bars match legend colors exactly (e.g., ARTIST bars are teal in both charts)
### Detailed Analysis
#### τ-bench Dataset
- **Airline**:
- Base Model: ~0.12
- Base Model + Reasoning: ~0.12
- ARTIST: ~0.26
- **Retail**:
- Base Model: ~0.18
- Base Model + Reasoning: ~0.20
- ARTIST: ~0.24
#### BFCL V3 Dataset
- **Missing Function**:
- Base Model: ~0.08
- Base Model + Reasoning: ~0.10
- ARTIST: ~0.11
- **Missing Parameters**:
- Base Model: ~0.06
- Base Model + Reasoning: ~0.05
- ARTIST: ~0.07
- **Long Context**:
- Base Model: ~0.04
- Base Model + Reasoning: ~0.05
- ARTIST: ~0.13
### Key Observations
1. **ARTIST Dominance**:
- ARTIST consistently outperforms other models in both datasets, with the largest gap in τ-bench's "Airline" category (0.26 vs. 0.12).
2. **Reasoning Impact**:
- "Base Model + Reasoning" matches or slightly exceeds the Base Model in most cases (e.g., Retail: 0.20 vs. 0.18), but underperforms ARTIST.
3. **BFCL V3 Anomaly**:
- ARTIST shows a dramatic improvement in "Long Context" (0.13 vs. 0.05 for Base Model + Reasoning), suggesting specialized handling of complex tasks.
4. **Missing Parameters Paradox**:
- Base Model + Reasoning performs worse than the Base Model in BFCL V3's "Missing Parameters" (0.05 vs. 0.06), indicating potential overfitting or task-specific limitations.
### Interpretation
The data demonstrates that ARTIST's architecture provides superior generalization across diverse tasks and datasets. The "Reasoning" augmentation improves Base Model performance modestly but fails to close the gap with ARTIST. Notably, ARTIST's exceptional performance in BFCL V3's "Long Context" task suggests it may leverage contextual understanding more effectively, possibly through architectural innovations like attention mechanisms or hierarchical processing. The anomaly in "Missing Parameters" warrants further investigation—it could indicate that reasoning introduces noise in parameter-sparse scenarios or that the Base Model's simplicity better handles edge cases. These findings highlight the importance of model architecture design over incremental improvements like reasoning layers for achieving state-of-the-art accuracy.