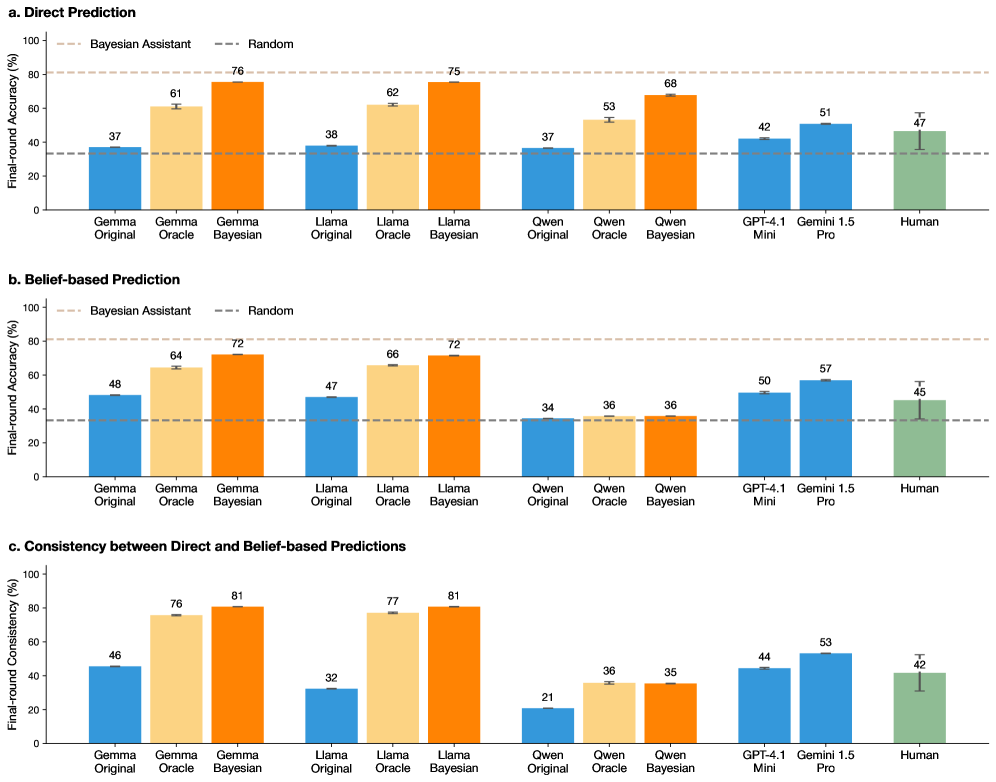
## Bar Charts: Model Performance Comparison
### Overview
The image presents three bar charts comparing the performance of various language models (Gemma, Llama, Qwen, GPT-4.1, Gemini 1.5) and human performance on a task. The charts depict "Final-round Accuracy (%)" or "Final-round Consistency (%)" on the y-axis, with different model configurations (Original, Oracle, Bayesian) on the x-axis. The charts compare "Direct Prediction", "Belief-based Prediction", and "Consistency between Direct and Belief-based Predictions". Horizontal dashed lines represent the performance of a "Bayesian Assistant" and a "Random" baseline.
### Components/Axes
**General Chart Elements:**
* **Title:** The image contains three sub-charts labeled "a. Direct Prediction", "b. Belief-based Prediction", and "c. Consistency between Direct and Belief-based Predictions".
* **Y-axis:** Labeled "Final-round Accuracy (%)" for charts a and b, and "Final-round Consistency (%)" for chart c. The scale ranges from 0 to 100 in increments of 20.
* **X-axis:** Categorical axis representing different language models and configurations: Gemma (Original, Oracle, Bayesian), Llama (Original, Oracle, Bayesian), Qwen (Original, Oracle, Bayesian), GPT-4.1 Mini, Gemini 1.5 Pro, and Human.
* **Bars:** Represent the performance of each model/configuration.
* **Error Bars:** Small vertical lines on top of each bar, indicating the standard error or confidence interval.
* **Horizontal Dashed Lines:** Two horizontal dashed lines representing the performance of "Bayesian Assistant" (top line) and "Random" (bottom line).
**Legend (Inferred):**
* Blue bars: "Original" model configuration.
* Light Orange bars: "Oracle" model configuration.
* Dark Orange bars: "Bayesian" model configuration.
* Green bars: "Human" performance.
### Detailed Analysis
#### a. Direct Prediction
* **Y-axis:** Final-round Accuracy (%)
* **Bayesian Assistant Baseline:** Approximately 80%
* **Random Baseline:** Approximately 35%
**Data Points:**
* **Gemma Original:** 37%
* **Gemma Oracle:** 61%
* **Gemma Bayesian:** 76%
* **Llama Original:** 38%
* **Llama Oracle:** 62%
* **Llama Bayesian:** 75%
* **Qwen Original:** 37%
* **Qwen Oracle:** 53%
* **Qwen Bayesian:** 68%
* **GPT-4.1 Mini:** 42%
* **Gemini 1.5 Pro:** 51%
* **Human:** 47%
**Trends:**
* For Gemma, Llama, and Qwen, the Bayesian configuration consistently outperforms the Oracle and Original configurations.
* GPT-4.1 Mini and Gemini 1.5 Pro perform similarly to each other.
* Human performance is comparable to GPT-4.1 Mini and Gemini 1.5 Pro.
#### b. Belief-based Prediction
* **Y-axis:** Final-round Accuracy (%)
* **Bayesian Assistant Baseline:** Approximately 80%
* **Random Baseline:** Approximately 35%
**Data Points:**
* **Gemma Original:** 48%
* **Gemma Oracle:** 64%
* **Gemma Bayesian:** 72%
* **Llama Original:** 47%
* **Llama Oracle:** 66%
* **Llama Bayesian:** 72%
* **Qwen Original:** 34%
* **Qwen Oracle:** 36%
* **Qwen Bayesian:** 36%
* **GPT-4.1 Mini:** 50%
* **Gemini 1.5 Pro:** 57%
* **Human:** 45%
**Trends:**
* Similar to Direct Prediction, the Bayesian configuration generally outperforms the Oracle and Original configurations for Gemma and Llama.
* Qwen's performance is relatively flat across all three configurations.
* GPT-4.1 Mini and Gemini 1.5 Pro show improved performance compared to the Direct Prediction chart.
* Human performance is slightly lower than in the Direct Prediction chart.
#### c. Consistency between Direct and Belief-based Predictions
* **Y-axis:** Final-round Consistency (%)
* **Bayesian Assistant Baseline:** Not applicable in this chart.
* **Random Baseline:** Not applicable in this chart.
**Data Points:**
* **Gemma Original:** 46%
* **Gemma Oracle:** 76%
* **Gemma Bayesian:** 81%
* **Llama Original:** 32%
* **Llama Oracle:** 77%
* **Llama Bayesian:** 81%
* **Qwen Original:** 21%
* **Qwen Oracle:** 36%
* **Qwen Bayesian:** 35%
* **GPT-4.1 Mini:** 44%
* **Gemini 1.5 Pro:** 53%
* **Human:** 42%
**Trends:**
* The Bayesian and Oracle configurations for Gemma and Llama show significantly higher consistency than the Original configurations.
* Qwen's consistency is notably lower compared to other models.
* GPT-4.1 Mini and Gemini 1.5 Pro show moderate consistency.
* Human consistency is relatively low.
### Key Observations
* The "Bayesian" configurations of Gemma and Llama consistently achieve the highest accuracy and consistency across all three charts.
* Qwen's performance is generally lower and more consistent across different configurations, especially in the "Belief-based Prediction" and "Consistency" charts.
* GPT-4.1 Mini and Gemini 1.5 Pro show comparable performance, often outperforming the "Original" configurations of Gemma, Llama, and Qwen.
* Human performance varies across the charts, sometimes exceeding the performance of certain models but generally falling within the range of GPT-4.1 Mini and Gemini 1.5 Pro.
### Interpretation
The data suggests that incorporating Bayesian methods into language models can significantly improve their accuracy and consistency in both direct and belief-based predictions. The "Oracle" configurations also show substantial improvements over the "Original" models, indicating the value of informed model design.
The relatively low consistency of Qwen suggests that its predictions may be less reliable or more sensitive to the specific task or context. The performance of GPT-4.1 Mini and Gemini 1.5 Pro highlights the capabilities of larger, more advanced models.
The variability in human performance underscores the challenges of evaluating language models against human benchmarks, as human performance itself can be inconsistent. The fact that human performance is sometimes worse than the models suggests that the models are in some cases better than humans.
The relationship between the charts is that they show different aspects of model performance. "Direct Prediction" measures raw accuracy, "Belief-based Prediction" measures accuracy when considering the model's confidence, and "Consistency" measures how well the model's direct and belief-based predictions align.