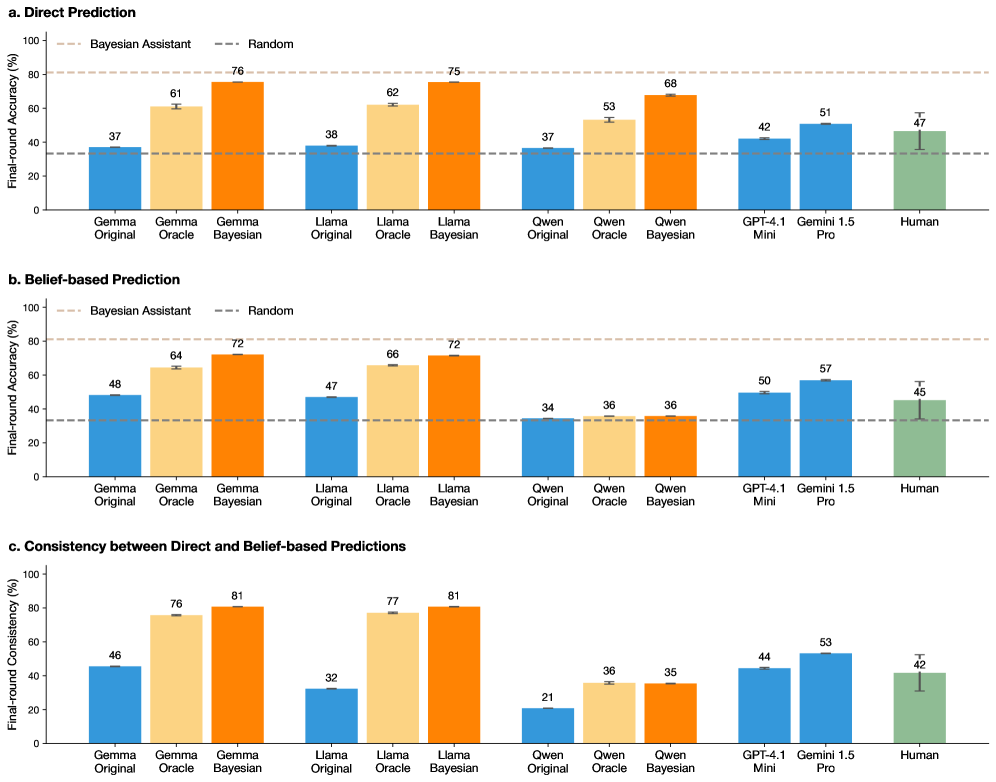
## Bar Charts: Comparison of AI Models and Human Performance Across Prediction Metrics
### Overview
The image contains three grouped bar charts comparing the performance of various AI models (Gemini, Llama, Qwen, GPT-4.1 Mini, Gemini 1.5 Pro) and humans across three metrics:
1. **Direct Prediction** (Chart a)
2. **Belief-based Prediction** (Chart b)
3. **Consistency between Direct and Belief-based Predictions** (Chart c)
Each chart evaluates final-round accuracy (%) against a "Random" baseline (blue dashed line) and a "Bayesian Assistant" benchmark (orange bars).
### Components/Axes
- **X-axis**: Models/human (Gemini Original, Gemini Oracle, Gemini Bayesian, Llama Original, Llama Oracle, Llama Bayesian, Qwen Original, Qwen Oracle, Qwen Bayesian, GPT-4.1 Mini, Gemini 1.5 Pro, Human).
- **Y-axis**: Final-round accuracy (%) from 0 to 100.
- **Legends**:
- **Bayesian Assistant**: Orange bars (Bayesian-enhanced models).
- **Random**: Blue dashed line (baseline performance).
- **Spatial Grounding**:
- Legends are positioned on the right of each chart.
- X-axis labels are centered below each chart; y-axis labels are on the left.
### Detailed Analysis
#### Chart a: Direct Prediction
- **Bayesian Models**:
- Gemini Bayesian: 76%
- Llama Bayesian: 75%
- Qwen Bayesian: 68%
- **Non-Bayesian Models**:
- Gemini Original: 37%
- Llama Original: 38%
- Qwen Original: 37%
- **Human**: 47%
#### Chart b: Belief-based Prediction
- **Bayesian Models**:
- Gemini Bayesian: 72%
- Llama Bayesian: 72%
- Qwen Bayesian: 36%
- **Non-Bayesian Models**:
- Gemini Original: 48%
- Llama Original: 47%
- Qwen Original: 34%
- **Human**: 45%
#### Chart c: Consistency between Direct and Belief-based Predictions
- **Bayesian Models**:
- Gemini Bayesian: 81%
- Llama Bayesian: 81%
- Qwen Bayesian: 35%
- **Non-Bayesian Models**:
- Gemini Original: 46%
- Llama Original: 32%
- Qwen Original: 21%
- **Human**: 42%
### Key Observations
1. **Bayesian Models Outperform Others**:
- Gemini and Llama Bayesian models consistently achieve the highest accuracy across all metrics (e.g., 76% in Direct Prediction, 81% in Consistency).
- Qwen Bayesian underperforms relative to its non-Bayesian counterpart in Belief-based Prediction (36% vs. 34%).
2. **Human Performance**:
- Humans score mid-range (42–47%) across metrics, outperforming non-Bayesian models but trailing Bayesian models.
3. **Qwen Anomalies**:
- Qwen Bayesian shows inconsistent results: 68% in Direct Prediction but only 35% in Consistency.
4. **Random Baseline**:
- All models and humans exceed the Random baseline (34–38%), indicating meaningful performance.
### Interpretation
- **Bayesian Advantage**: The use of Bayesian methods (e.g., Gemini Bayesian, Llama Bayesian) significantly improves accuracy and consistency, suggesting these models better integrate prior knowledge or uncertainty.
- **Qwen’s Limitations**: Qwen’s Bayesian implementation appears less effective, possibly due to architectural constraints or training data gaps.
- **Human vs. AI**: While humans outperform non-Bayesian models, they lag behind advanced Bayesian AI, highlighting the latter’s potential for complex reasoning tasks.
- **Consistency as a Proxy for Reliability**: High consistency scores (e.g., 81% for Gemini Bayesian) indicate stable performance across prediction types, a critical factor for real-world applications.
This analysis underscores the transformative impact of Bayesian approaches in AI systems, particularly for tasks requiring robust and reliable predictions.