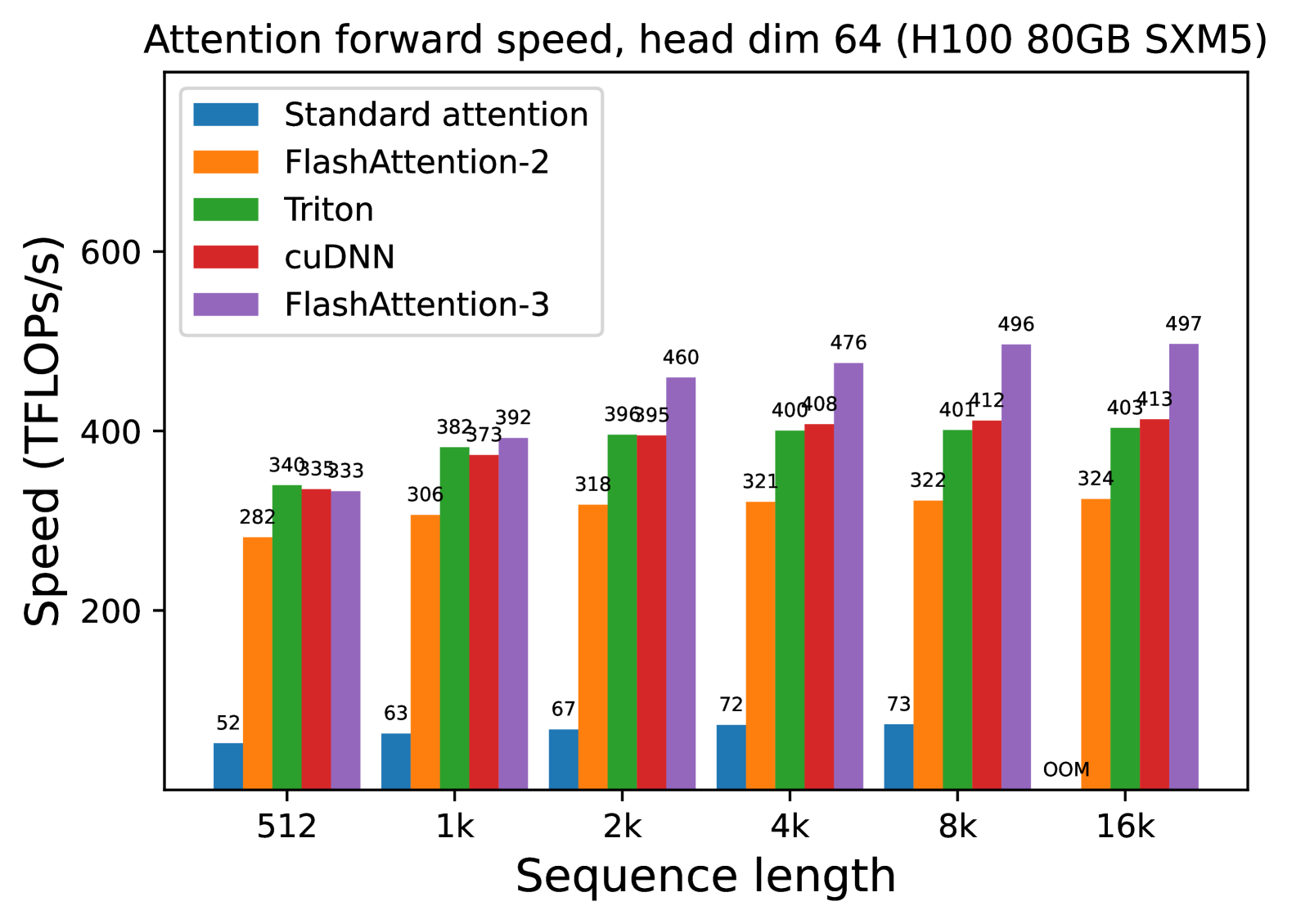
# Technical Document: Attention Forward Speed Analysis
## Chart Title
Attention forward speed, head dim 64 (H100 80GB SXM5)
## Axes
- **X-axis**: Sequence length
Categories: `512`, `1k`, `2k`, `4k`, `8k`, `16k`
- **Y-axis**: Speed (TFLOPs/s)
Range: 0–600 (discrete increments)
## Legend
| Color | Method |
|-------------|----------------------|
| Blue | Standard attention |
| Orange | FlashAttention-2 |
| Green | Triton |
| Red | cuDNN |
| Purple | FlashAttention-3 |
## Data Points
### Sequence Length: 512
- Standard attention: 52 TFLOPs/s
- FlashAttention-2: 282 TFLOPs/s
- Triton: 340 TFLOPs/s
- cuDNN: 335 TFLOPs/s
- FlashAttention-3: 333 TFLOPs/s
### Sequence Length: 1k
- Standard attention: 63 TFLOPs/s
- FlashAttention-2: 306 TFLOPs/s
- Triton: 382 TFLOPs/s
- cuDNN: 373 TFLOPs/s
- FlashAttention-3: 392 TFLOPs/s
### Sequence Length: 2k
- Standard attention: 67 TFLOPs/s
- FlashAttention-2: 318 TFLOPs/s
- Triton: 396 TFLOPs/s
- cuDNN: 395 TFLOPs/s
- FlashAttention-3: 460 TFLOPs/s
### Sequence Length: 4k
- Standard attention: 72 TFLOPs/s
- FlashAttention-2: 321 TFLOPs/s
- Triton: 400 TFLOPs/s
- cuDNN: 408 TFLOPs/s
- FlashAttention-3: 476 TFLOPs/s
### Sequence Length: 8k
- Standard attention: 73 TFLOPs/s
- FlashAttention-2: 322 TFLOPs/s
- Triton: 401 TFLOPs/s
- cuDNN: 412 TFLOPs/s
- FlashAttention-3: 496 TFLOPs/s
### Sequence Length: 16k
- Standard attention: **OOM** (Out of Memory)
- FlashAttention-2: 324 TFLOPs/s
- Triton: 403 TFLOPs/s
- cuDNN: 413 TFLOPs/s
- FlashAttention-3: 497 TFLOPs/s
## Key Trends
1. **Performance Scaling**:
- All methods show increased speed with longer sequence lengths, except Standard attention (OOM at 16k).
- FlashAttention-3 consistently outperforms other methods across all sequence lengths.
2. **Standard Attention Limitations**:
- Significantly lower performance than other methods.
- Fails at 16k sequence length (OOM).
3. **Relative Efficiency**:
- Triton and cuDNN exhibit similar performance, trailing FlashAttention-3 but outperforming FlashAttention-2.
- FlashAttention-2 lags behind Triton and cuDNN but remains viable for shorter sequences.
## Notes
- **Hardware**: H100 80GB SXM5 GPU
- **Head Dimension**: 64
- **OOM**: Indicates out-of-memory errors for Standard attention at 16k sequence length.