## Diagram: Two-Stage Model Architecture
### Overview
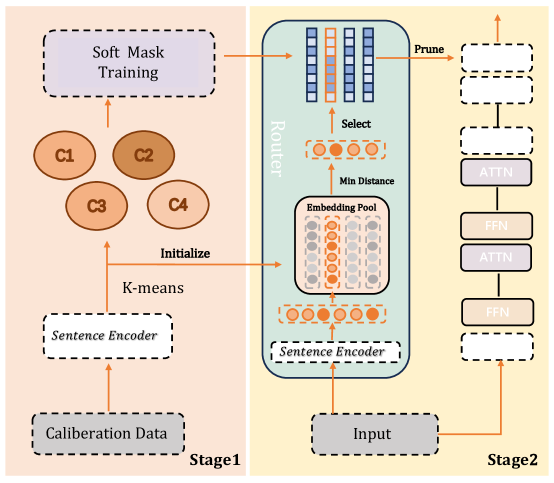
The image presents a two-stage model architecture, likely for natural language processing. Stage 1 focuses on data calibration and initialization using K-means clustering, while Stage 2 involves routing, embedding, and attention mechanisms.
### Components/Axes
**Stage 1 (Left, Peach Background):**
* **Calibration Data:** A dashed-line box at the bottom-left.
* **Sentence Encoder:** A dashed-line box above "Calibration Data".
* **K-means:** Text label with an arrow pointing upwards.
* **C1, C2, C3, C4:** Four circles, representing clusters. C2 is slightly darker than the others.
* **Soft Mask Training:** A dashed-line box at the top-left.
**Stage 2 (Right, Light Yellow Background):**
* **Input:** A dashed-line box at the bottom.
* **Router:** A rounded rectangle containing several components.
* **Sentence Encoder:** A dashed-line box at the bottom of the Router.
* **Embedding Pool:** A collection of circles, some filled with orange and some gray.
* **Min Distance:** Text label with an arrow pointing upwards.
* **Select:** Text label with an arrow pointing upwards.
* A stack of blue rectangles at the top of the Router, some with orange highlights.
* **Prune:** Text label with an arrow pointing to a stack of two dashed-line boxes.
* **FFN, ATTN:** Alternating blocks of "FFN" (Feed Forward Network) and "ATTN" (Attention) modules.
### Detailed Analysis
**Stage 1:**
* Calibration Data is fed into a Sentence Encoder.
* The output of the Sentence Encoder is used for K-means clustering, resulting in four clusters (C1, C2, C3, C4).
* These clusters initialize the Soft Mask Training process.
**Stage 2:**
* Input is fed into a Sentence Encoder within the Router.
* The output of the Sentence Encoder goes into the Embedding Pool.
* "Min Distance" is calculated, and a selection is made.
* The selected embeddings are then processed through a series of blue rectangles.
* The "Prune" operation leads to a stack of two dashed-line boxes.
* The pruned output is then processed through alternating layers of FFN and ATTN.
### Key Observations
* The diagram illustrates a sequential flow of data and processing steps.
* K-means clustering in Stage 1 initializes the Soft Mask Training.
* The Router in Stage 2 appears to be a key component for embedding selection and pruning.
* The alternating FFN and ATTN layers suggest a transformer-based architecture.
### Interpretation
The diagram depicts a two-stage model designed for a specific NLP task. Stage 1 focuses on data preparation and initialization, likely to improve the efficiency or accuracy of the subsequent stages. The K-means clustering suggests that the model is designed to handle different types of input data, with each cluster representing a distinct category or feature. Stage 2 implements a more complex architecture, potentially involving attention mechanisms and pruning techniques to optimize performance. The "Router" component seems to play a crucial role in selecting and routing relevant information within the model. The overall architecture suggests a sophisticated approach to NLP, combining data-driven initialization with advanced neural network techniques.