\n
## Diagram: Two-Stage Model Architecture
### Overview
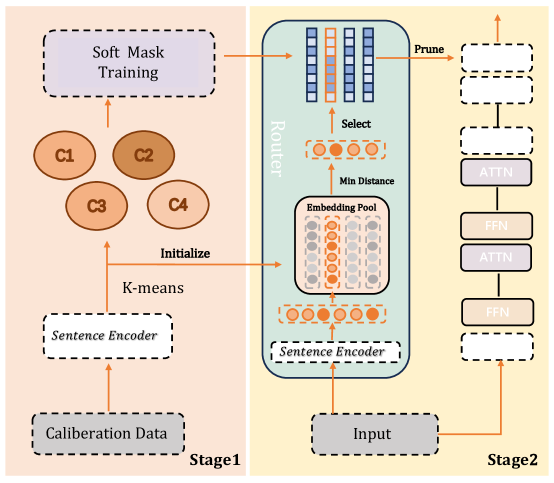
The image depicts a two-stage model architecture, likely for a machine learning or natural language processing task. Stage 1 focuses on initialization and clustering, while Stage 2 appears to be a refinement or processing stage. The diagram illustrates the flow of data and operations between different components.
### Components/Axes
The diagram is divided into two main sections labeled "Stage1" and "Stage2", positioned side-by-side. Key components include: "Calibration Data", "Sentence Encoder", "K-means", "Soft Mask Training", "Router", "Embedding Pool", "Prune", "Select", "Min Distance", "ATTN", and "FFN". There are also four clusters labeled "C1", "C2", "C3", and "C4". Arrows indicate the direction of data flow.
### Detailed Analysis or Content Details
**Stage 1 (Left Side):**
* **Calibration Data:** Input to the "Sentence Encoder".
* **Sentence Encoder:** Processes "Calibration Data" and outputs to "K-means".
* **K-means:** Initializes four clusters labeled "C1", "C2", "C3", and "C4". The output of "K-means" is fed into "Soft Mask Training".
* **Soft Mask Training:** Receives input from "K-means" and outputs to the "Router" in Stage 2.
**Stage 2 (Right Side):**
* **Input:** Input to the "Sentence Encoder".
* **Sentence Encoder:** Processes "Input" and outputs to the "Embedding Pool".
* **Embedding Pool:** Contains a series of circles representing embeddings. This output is fed into the "Router".
* **Router:** Receives input from "Soft Mask Training" (Stage 1) and "Embedding Pool". It performs "Select" and "Prune" operations.
* **Prune:** Filters the output of the "Router".
* **Select:** Selects data from the "Router".
* **Min Distance:** A component within the "Router" that calculates minimum distances.
* **ATTN:** (Attention Mechanism) Appears twice in a stacked configuration.
* **FFN:** (Feed Forward Network) Appears twice in a stacked configuration, interleaved with "ATTN".
* The output of the "Router" (after "Prune") is fed into a series of "ATTN" and "FFN" layers.
**Data Flow:**
* Data flows from "Calibration Data" through "Sentence Encoder" to "K-means", then to "Soft Mask Training".
* Data flows from "Input" through "Sentence Encoder" to "Embedding Pool".
* "Soft Mask Training" and "Embedding Pool" both feed into the "Router".
* The "Router" processes data and sends it through "ATTN" and "FFN" layers.
### Key Observations
The diagram highlights a two-stage process. Stage 1 appears to be a clustering or initialization phase, while Stage 2 is a processing or refinement phase. The "Router" component seems central to integrating information from both stages. The repeated "ATTN" and "FFN" layers suggest a deep learning architecture.
### Interpretation
This diagram likely represents a model that uses a clustering approach (K-means) to initialize a soft mask, which is then used to guide the processing of input data. The "Router" acts as a gatekeeper, selecting and pruning information based on the initialized clusters. The subsequent "ATTN" and "FFN" layers suggest a mechanism for learning complex relationships within the data. The two-stage approach could be designed to improve efficiency or performance by first establishing a coarse-grained representation of the data (Stage 1) and then refining it (Stage 2). The use of "Soft Mask Training" suggests a probabilistic or fuzzy approach to clustering, allowing for overlapping cluster assignments. The diagram does not provide specific numerical data or performance metrics, but it clearly outlines the architectural components and their interconnections.