TECHNICAL ASSET FINGERPRINT
560a678755571eaf696cbefc
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
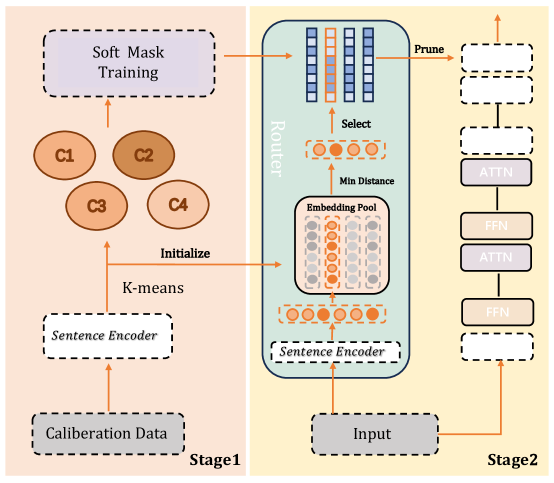
## Process Flow Diagram: Two-Stage Model Pruning Framework
### Overview
This image is a technical process flow diagram illustrating a two-stage framework for neural network model compression or pruning. The diagram is divided into two distinct panels: **Stage1** (left, light orange background) and **Stage2** (right, light yellow background). The overall flow describes a method that uses calibration data to train a "soft mask," which is then used to guide the pruning of a target model during inference.
### Components/Flow
The diagram consists of labeled boxes, circles, arrows, and a large containing block, all representing components and data flow.
**Stage1 (Left Panel):**
* **Bottom Component:** A dashed box labeled `Calibration Data`.
* **Flow Arrow:** An upward arrow points from `Calibration Data` to a dashed box labeled `Sentence Encoder`.
* **Clustering:** An upward arrow labeled `K-means` points from `Sentence Encoder` to four circles labeled `C1`, `C2`, `C3`, and `C4`. These represent clusters.
* **Training:** An upward arrow points from the cluster circles to a dashed box at the top labeled `Soft Mask Training`.
* **Initialization Link:** A horizontal arrow labeled `Initialize` points from the `K-means` arrow (between Sentence Encoder and clusters) to the `Embedding Pool` in Stage2.
**Stage2 (Right Panel):**
* **Input Flow:** At the bottom, a solid box labeled `Input` has two output arrows:
1. One arrow goes up to a dashed box labeled `Sentence Encoder`.
2. Another arrow goes right to a dashed box at the base of a model stack.
* **Router Block:** A large, light-blue rounded rectangle labeled `Router` contains:
* **Embedding Pool:** A dashed box labeled `Embedding Pool` containing a grid of circles (some orange, some grey).
* **Selection Mechanism:** An arrow labeled `Min Distance` points from the `Embedding Pool` to a row of four orange circles. An arrow labeled `Select` points from these circles upward to a set of vertical bars (blue and orange).
* **Input to Router:** The `Sentence Encoder` from the Input feeds into the `Embedding Pool`.
* **Pruning Output:** An arrow labeled `Prune` points from the vertical bars in the Router to a stack of boxes on the far right.
* **Model Stack (Far Right):** A vertical stack of boxes representing neural network layers. From bottom to top:
* A dashed box (input layer).
* A solid box labeled `FFN`.
* A solid box labeled `ATTN`.
* A dashed box.
* A solid box labeled `FFN`.
* A solid box labeled `ATTN`.
* A dashed box.
* Three dashed boxes at the top.
* An upward arrow exits the top of the stack.
* **Label:** The entire right panel is labeled `Stage2` at the bottom right.
### Detailed Analysis
The diagram details a specific technical pipeline:
1. **Stage1 - Mask Training:**
* **Input:** `Calibration Data` is processed by a `Sentence Encoder`.
* **Process:** The encoded data is clustered using `K-means` into groups `C1-C4`.
* **Output:** These clusters are used for `Soft Mask Training`, presumably to learn which parts of a model (or embedding space) are important. The `Initialize` arrow suggests the clusters or their centroids are used to initialize the `Embedding Pool` in Stage2.
2. **Stage2 - Dynamic Pruning/Inference:**
* **Input Processing:** A new `Input` is encoded by a `Sentence Encoder`.
* **Routing:** The encoded input enters the `Router`'s `Embedding Pool`. The system finds the `Min Distance` (likely cosine or Euclidean) between the input embedding and the pool entries.
* **Selection:** Based on minimum distance, a subset of embeddings (the four orange circles) is `Select`ed. This selection influences which model components (represented by the vertical bars) are activated or used.
* **Pruning:** The `Prune` action results in a sparse model stack on the right. The stack shows alternating `ATTN` (Attention) and `FFN` (Feed-Forward Network) layers. The dashed boxes represent layers or components that have been pruned (removed or deactivated), while solid boxes remain active. The final output is produced by this pruned model.
### Key Observations
* **Two-Stage Process:** The framework clearly separates the training of a pruning guide (Stage1) from its application during inference (Stage2).
* **Dynamic Routing:** The core of Stage2 is a `Router` that performs a nearest-neighbor search (`Min Distance`) in an `Embedding Pool` to dynamically select a sub-network for each input.
* **Visual Coding:** Dashed lines consistently represent components involved in training or that are pruned/inactive (`Calibration Data`, `Sentence Encoder` in Stage1, pruned layers in the model stack). Solid lines represent active inference components (`Input`, `FFN`/`ATTN` layers).
* **Cluster-Based Initialization:** The `K-means` clusters (`C1-C4`) from Stage1 directly initialize the `Embedding Pool` in Stage2, linking the two stages.
* **Asymmetric Layout:** The `Router` is a large, central component in Stage2, emphasizing its importance. The final model stack is off to the right, showing the outcome of the routing/pruning.
### Interpretation
This diagram illustrates a **dynamic network pruning or conditional computation** technique, likely for natural language processing models given the use of `Sentence Encoder`.
* **What it does:** The system learns a compact set of "prototype" embeddings (the `Embedding Pool`) from calibration data. During inference, for each new input, it finds the most similar prototypes and activates only the part of the neural network (a specific sub-network of `ATTN` and `FFN` layers) associated with those prototypes. This reduces computation by avoiding the full model for every input.
* **How elements relate:** Stage1 is the offline, data-dependent setup phase that creates the routing mechanism. Stage2 is the online, efficient inference phase that uses that mechanism. The `Router` is the critical bridge, translating input similarity into architectural selection.
* **Notable implications:** This approach promises significant efficiency gains (speed, memory) by adapting the model's capacity to each input. The "soft mask" from Stage1 likely determines the importance of different model parameters, which the `Router` uses to make selection decisions. The pruned model stack visually demonstrates the resulting sparse activation pattern. The framework appears designed to maintain model accuracy while reducing computational cost, a key challenge in deploying large language models.
DECODING INTELLIGENCE...