\n
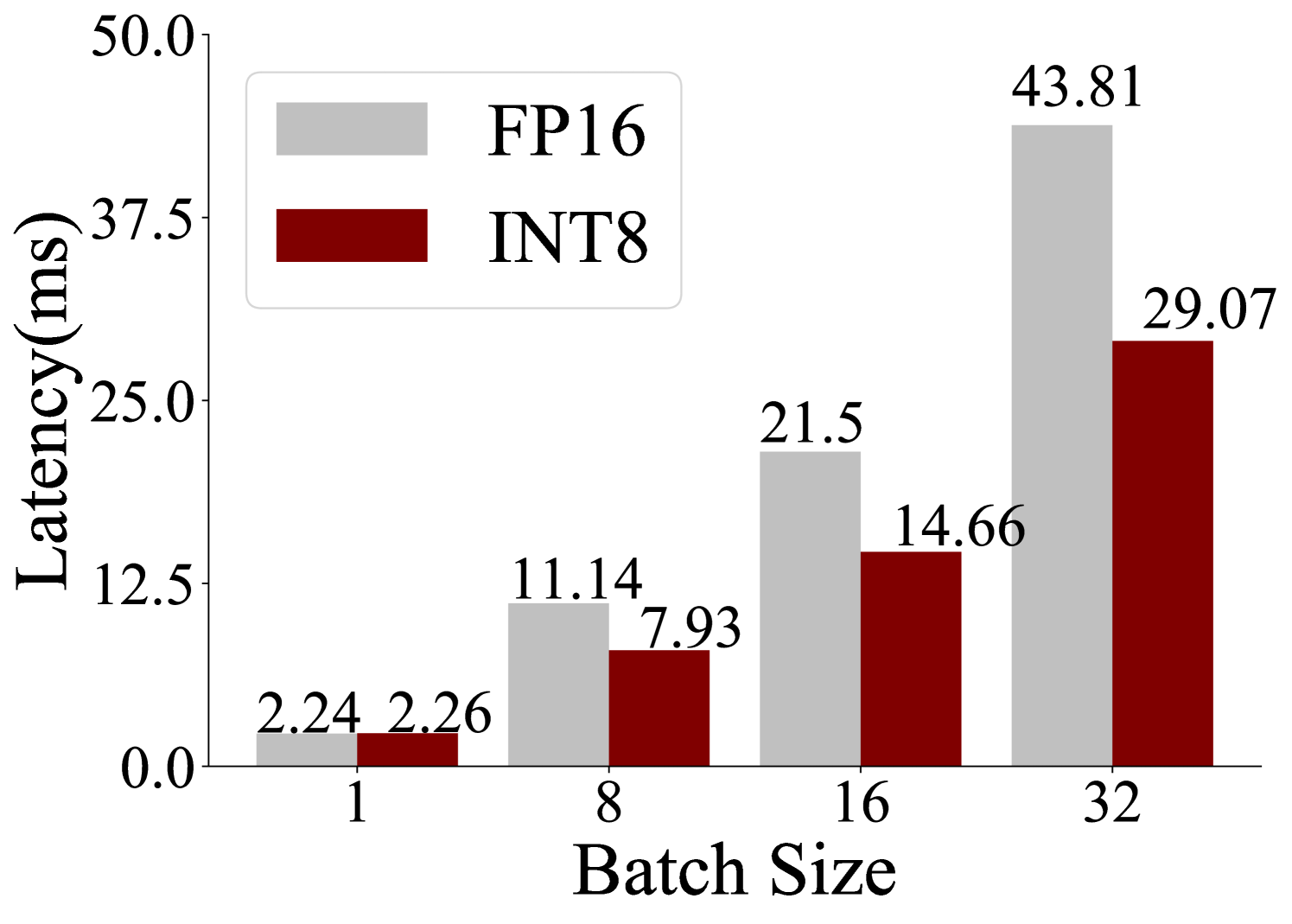
## Bar Chart: Latency vs. Batch Size for FP16 and INT8
### Overview
This bar chart compares the latency (in milliseconds) of operations performed using FP16 and INT8 data types across different batch sizes. The x-axis represents the batch size, and the y-axis represents the latency. The chart displays latency values for each batch size and data type combination.
### Components/Axes
* **X-axis:** Batch Size (with markers at 1, 8, 16, and 32)
* **Y-axis:** Latency (ms), ranging from 0.0 to 50.0
* **Legend:**
* FP16 (represented by light gray bars)
* INT8 (represented by dark red bars)
* **Data Series:** Two data series, one for FP16 and one for INT8.
### Detailed Analysis
The chart presents latency values for four batch sizes (1, 8, 16, and 32) and two data types (FP16 and INT8).
* **Batch Size 1:**
* FP16: 2.24 ms
* INT8: 2.26 ms
* **Batch Size 8:**
* FP16: 11.14 ms
* INT8: 7.93 ms
* **Batch Size 16:**
* FP16: 21.5 ms
* INT8: 14.66 ms
* **Batch Size 32:**
* FP16: 43.81 ms
* INT8: 29.07 ms
**Trends:**
* **FP16:** The FP16 latency increases almost linearly with batch size. The line slopes upward.
* **INT8:** The INT8 latency also increases with batch size, but at a slower rate than FP16. The line slopes upward, but less steeply.
### Key Observations
* INT8 consistently exhibits lower latency than FP16 across all batch sizes.
* The difference in latency between FP16 and INT8 becomes more pronounced as the batch size increases.
* The latency increases significantly as the batch size increases for both data types.
### Interpretation
The data suggests that using INT8 quantization can significantly reduce latency compared to FP16, especially when processing larger batches of data. This is likely due to the reduced memory footprint and computational complexity associated with INT8 operations. The linear increase in latency with batch size indicates that the processing time scales with the amount of data being processed. The widening gap between FP16 and INT8 latency as batch size increases suggests that the benefits of INT8 quantization become more substantial when dealing with larger workloads. This chart demonstrates a clear trade-off between precision (FP16) and performance (INT8). The choice between the two would depend on the specific application's requirements for accuracy and speed.