TECHNICAL ASSET FINGERPRINT
568cd81694797bfbc862d818
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-3.1-pro-preview VERSION 1
RUNTIME: gemini/gemini-3.1-pro-preview
INTEL_VERIFIED
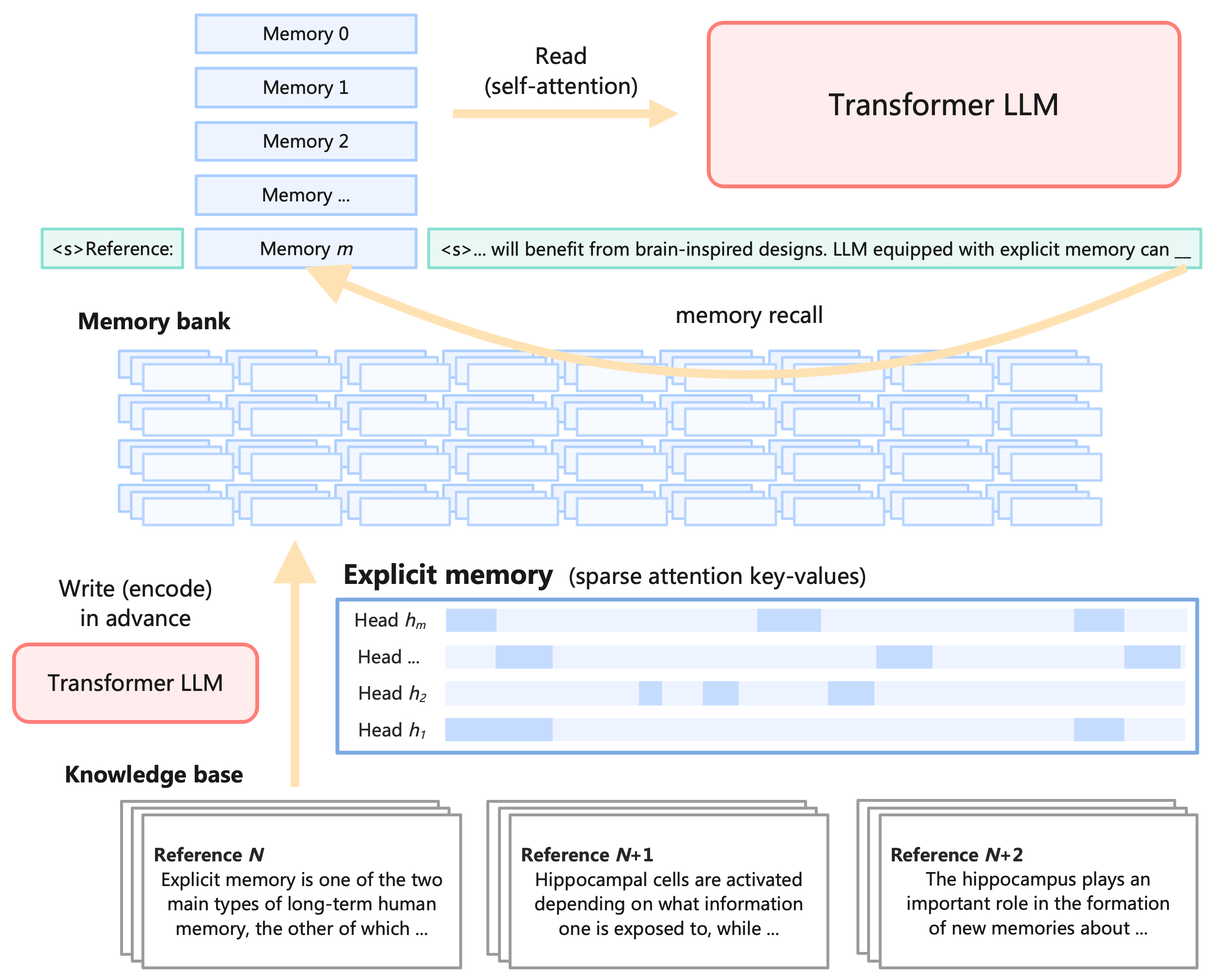
## Diagram: Transformer LLM with Explicit Memory Bank Architecture
### Overview
This image is a technical system architecture diagram illustrating a framework where a Transformer Large Language Model (LLM) is augmented with an external, explicit memory bank. The diagram is divided into three primary functional phases: encoding a knowledge base into memory (bottom), storing the memory using sparse attention (middle), and recalling/reading the memory during text generation (top).
### Components
The diagram consists of several distinct visual components, connected by directional arrows indicating data flow:
* **Knowledge base:** Document cards representing raw text data.
* **Transformer LLM (Write/Encode):** A processing module (red box) used to process the knowledge base.
* **Memory bank:** A large grid of blue rectangles representing stored encoded data.
* **Explicit memory (sparse attention key-values):** A detailed view of the memory structure showing attention heads and sparse activation patterns.
* **Transformer LLM (Read/Self-attention):** A processing module (red box) used for generating output based on recalled memory.
* **Input/Output Sequences:** Text strings enclosed in green-bordered boxes representing the prompt and the model's generation.
### Content Details
To ensure accurate extraction, the diagram is isolated into three spatial regions: Bottom (Encoding), Middle (Storage), and Top (Inference/Recall).
#### 1. Bottom Region: Knowledge Base and Encoding
* **Spatial Positioning:** Bottom of the image.
* **Label:** "Knowledge base" (bold text).
* **Visuals:** Three distinct stacks of document cards, arranged horizontally from left to right.
* **Transcriptions:**
* **Left Card:**
* Header: **Reference $N$**
* Body: "Explicit memory is one of the two main types of long-term human memory, the other of which ..."
* **Center Card:**
* Header: **Reference $N+1$**
* Body: "Hippocampal cells are activated depending on what information one is exposed to, while ..."
* **Right Card:**
* Header: **Reference $N+2$**
* Body: "The hippocampus plays an important role in the formation of new memories about ..."
* **Flow:** A vertical yellow arrow points upwards from the Knowledge base. To the left of this arrow is a light red box with a red border containing the text "Transformer LLM". Above this box is the text "Write (encode) in advance". The arrow points towards the "Memory bank" in the middle region.
#### 2. Middle Region: Memory Storage
* **Spatial Positioning:** Center of the image.
* **Label:** **Memory bank** (bold text, positioned above a grid).
* **Visuals (Left/Center):** A large, dense array of overlapping, empty light-blue rectangles, representing a vast storage of encoded memory blocks.
* **Label:** **Explicit memory** (sparse attention key-values) (positioned to the right).
* **Visuals (Right):** A large rectangular box with a blue border detailing the internal structure of the explicit memory. It contains four horizontal rows representing attention heads. Each row consists of a bar with alternating light-blue (shaded) and white (empty) segments, visually depicting sparsity.
* **Transcriptions (Bottom to Top within the box):**
* "Head $h_1$" (Shows shading at the beginning and near the end).
* "Head $h_2$" (Shows sparse shading in the middle).
* "Head ..." (Shows sparse shading in the early-middle and end).
* "Head $h_m$" (Shows sparse shading at the beginning, middle, and end).
#### 3. Top Region: Inference and Recall
* **Spatial Positioning:** Top of the image.
* **Visuals (Left):** A vertical stack of five light-blue rectangles.
* **Transcriptions (Top to Bottom within the stack):**
* "Memory 0"
* "Memory 1"
* "Memory 2"
* "Memory ..."
* "Memory $m$"
* **Contextual Text (Flanking "Memory $m$"):**
* To the left (in a green-bordered box): `<s>Reference:`
* To the right (in a green-bordered box): `<s>... will benefit from brain-inspired designs. LLM equipped with explicit memory can __`
* **Flow 1 (Recall):** A long, curved yellow arrow originates from the end of the text string (at the `__` underscore) and points backwards/leftwards, landing directly on the "Memory $m$" block. Above this curved arrow is the text "memory recall".
* **Flow 2 (Read):** A straight yellow arrow points to the right, originating from the stack of Memory blocks. Above and below this arrow is the text "Read (self-attention)".
* **Visuals (Right):** The straight arrow points into a large light-red box with a red border containing the text "Transformer LLM".
### Key Observations
* **Separation of Concerns:** The architecture explicitly separates the "Write (encode)" phase from the "Read (self-attention)" phase. The encoding happens "in advance," suggesting an offline or pre-computation step.
* **Sparsity:** The "Explicit memory" block visually demonstrates that not all memory is accessed at once; the blue shaded blocks in the attention heads indicate that only specific key-values are activated (sparse attention).
* **Biological Inspiration:** The text within the knowledge base explicitly references human biology ("long-term human memory", "Hippocampal cells", "hippocampus"), aligning with the prompt text mentioning "brain-inspired designs."
* **Mechanism of Action:** The curved "memory recall" arrow shows that the current generation context (the prompt) is used as a query to fetch a specific memory block ("Memory $m$") from the broader memory bank, which is then prepended or injected into the context (`<s>Reference:`) for the Transformer to read via self-attention.
### Interpretation
This diagram illustrates a Retrieval-Augmented Generation (RAG) or memory-augmented LLM architecture designed to bypass standard context window limitations.
Instead of feeding all reference documents directly into the LLM's prompt (which is computationally expensive and limited by token length), the system pre-processes a large "Knowledge base" using a Transformer to encode the text into a "Memory bank" of key-value pairs.
During inference, as the LLM generates text (e.g., "...equipped with explicit memory can __"), the current context triggers a "memory recall." This acts as a routing mechanism to find the most relevant pre-encoded memory block (in this case, "Memory $m$"). Because the memory utilizes "sparse attention," the system can efficiently search through massive amounts of data by only activating relevant attention heads.
Once the relevant memory block is retrieved, it is treated as a "Reference" and read by the Transformer LLM using standard self-attention to complete the generation. The inclusion of texts about the hippocampus strongly implies the authors are drawing a parallel between this artificial sparse-retrieval system and how the human brain stores and recalls long-term memories.
DECODING INTELLIGENCE...