## Chart Type: Pie Chart
### Overview
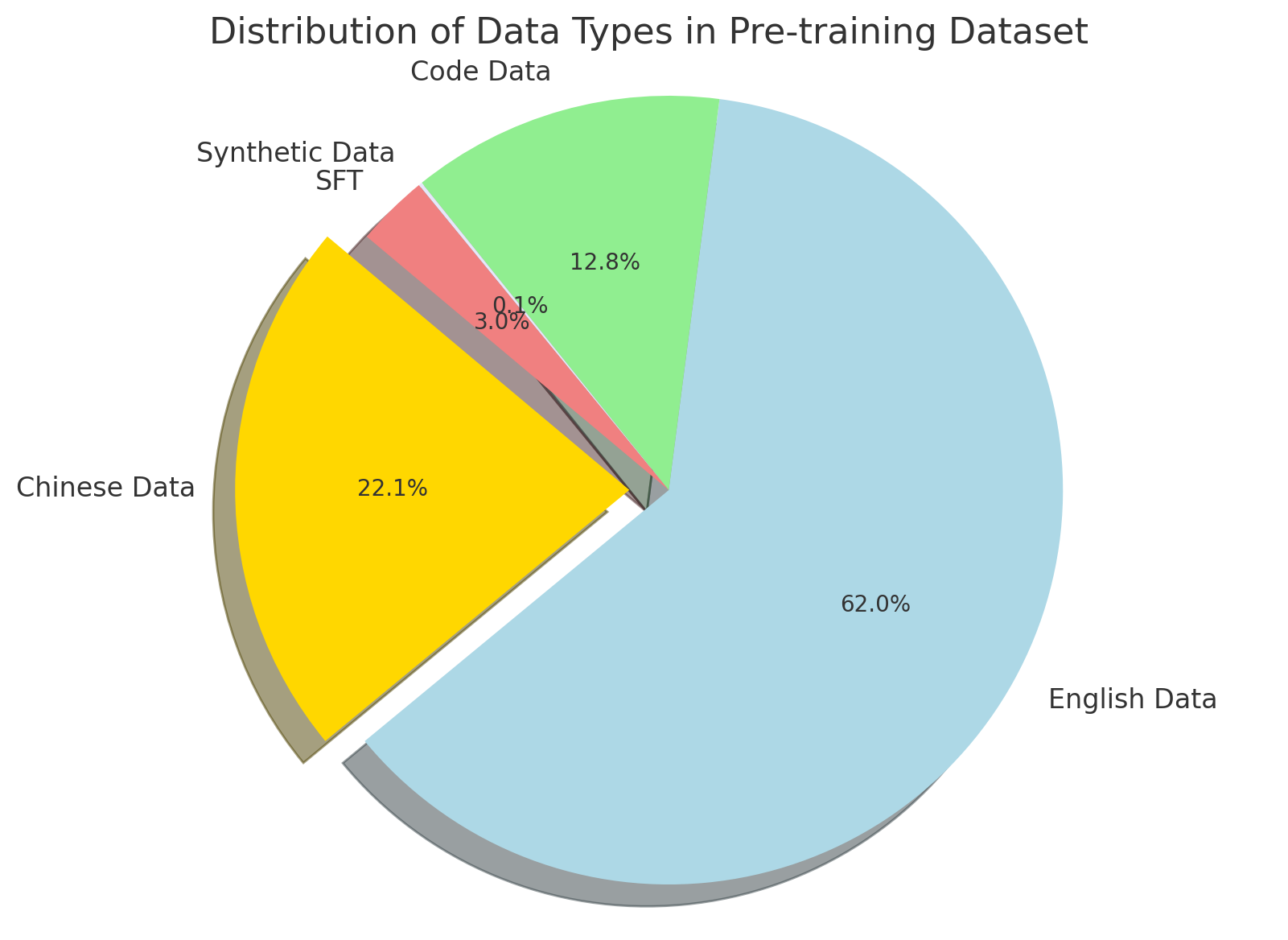
The image is a 3D pie chart illustrating the distribution of data types in a pre-training dataset. The chart shows the percentage breakdown of English Data, Chinese Data, Code Data, Synthetic Data (SFT), and a very small sliver of an unlabeled data type. The English Data makes up the majority of the dataset.
### Components/Axes
* **Title:** Distribution of Data Types in Pre-training Dataset
* **Categories:**
* English Data (light blue) - 62.0%
* Chinese Data (gold) - 22.1%
* Code Data (light green) - 12.8%
* Synthetic Data SFT (light red) - 3.0%
* Unlabeled Data (gray) - 0.1%
### Detailed Analysis
* **English Data:** The largest slice of the pie, colored light blue, represents 62.0% of the dataset.
* **Chinese Data:** The second largest slice, colored gold, represents 22.1% of the dataset. This slice is slightly separated from the rest of the pie chart, giving it emphasis.
* **Code Data:** The third largest slice, colored light green, represents 12.8% of the dataset.
* **Synthetic Data SFT:** A smaller slice, colored light red, represents 3.0% of the dataset.
* **Unlabeled Data:** A very small sliver, colored gray, represents 0.1% of the dataset.
### Key Observations
* English data dominates the pre-training dataset, accounting for nearly two-thirds of the total data.
* Chinese data is the second largest component, but significantly smaller than English data.
* The unlabeled data is a negligible portion of the dataset.
* The Chinese Data slice is visually separated from the rest of the pie, possibly to highlight its contribution.
### Interpretation
The pie chart provides a clear overview of the composition of the pre-training dataset. The dominance of English data suggests that the model trained on this dataset may be more proficient in English-related tasks. The presence of Chinese data indicates some multilingual capability. The small percentage of Synthetic Data (SFT) suggests that synthetic data augmentation may not be a primary focus. The unlabeled data is so small that it is likely negligible in the training process. The separation of the Chinese Data slice could indicate its importance or a specific focus during the data collection or pre-processing phase.