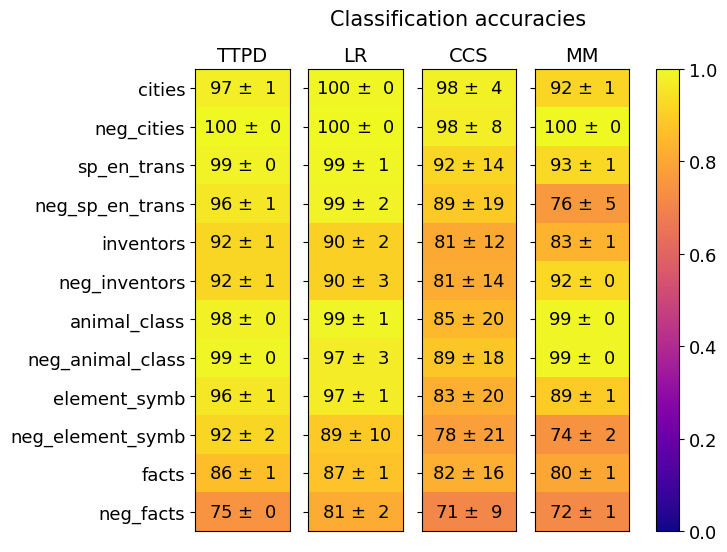
\n
## Heatmap: Classification Accuracies
### Overview
The image is a heatmap chart titled "Classification accuracies." It displays the performance (accuracy with standard deviation) of four different classification methods (TTPD, LR, CCS, MM) across twelve distinct datasets or tasks. The accuracy values are presented as percentages within each cell, and the cells are color-coded based on a scale from 0.0 to 1.0 (0% to 100%).
### Components/Axes
* **Title:** "Classification accuracies" (centered at the top).
* **Rows (Y-axis):** Twelve dataset/task labels, listed vertically on the left side. From top to bottom:
1. `cities`
2. `neg_cities`
3. `sp_en_trans`
4. `neg_sp_en_trans`
5. `inventors`
6. `neg_inventors`
7. `animal_class`
8. `neg_animal_class`
9. `element_symb`
10. `neg_element_symb`
11. `facts`
12. `neg_facts`
* **Columns (X-axis):** Four method labels, listed horizontally at the top. From left to right:
1. `TTPD`
2. `LR`
3. `CCS`
4. `MM`
* **Color Scale/Legend:** A vertical color bar is positioned on the far right of the chart. It maps colors to numerical accuracy values:
* **Scale:** 0.0 (bottom, dark purple) to 1.0 (top, bright yellow).
* **Gradient:** Transitions from dark purple (0.0-0.2) through magenta/red (0.4-0.6) and orange (0.8) to yellow (1.0).
* **Data Cells:** A 12x4 grid where each cell contains the text "Accuracy ± Standard Deviation" (e.g., "97 ± 1"). The background color of each cell corresponds to the accuracy value according to the color scale.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Values are "Accuracy ± Standard Deviation" (%).
| Dataset / Task | TTPD | LR | CCS | MM |
| :--- | :--- | :--- | :--- | :--- |
| **cities** | 97 ± 1 | 100 ± 0 | 98 ± 4 | 92 ± 1 |
| **neg_cities** | 100 ± 0 | 100 ± 0 | 98 ± 8 | 100 ± 0 |
| **sp_en_trans** | 99 ± 0 | 99 ± 1 | 92 ± 14 | 93 ± 1 |
| **neg_sp_en_trans** | 96 ± 1 | 99 ± 2 | 89 ± 19 | 76 ± 5 |
| **inventors** | 92 ± 1 | 90 ± 2 | 81 ± 12 | 83 ± 1 |
| **neg_inventors** | 92 ± 1 | 90 ± 3 | 81 ± 14 | 92 ± 0 |
| **animal_class** | 98 ± 0 | 99 ± 1 | 85 ± 20 | 99 ± 0 |
| **neg_animal_class** | 99 ± 0 | 97 ± 3 | 89 ± 18 | 99 ± 0 |
| **element_symb** | 96 ± 1 | 97 ± 1 | 83 ± 20 | 89 ± 1 |
| **neg_element_symb** | 92 ± 2 | 89 ± 10 | 78 ± 21 | 74 ± 2 |
| **facts** | 86 ± 1 | 87 ± 1 | 82 ± 16 | 80 ± 1 |
| **neg_facts** | 75 ± 0 | 81 ± 2 | 71 ± 9 | 72 ± 1 |
**Visual Trend Verification:**
* **Color Trend:** The dominant color across the top rows (`cities`, `neg_cities`, `sp_en_trans`, `animal_class`) is bright yellow, indicating very high accuracy (near 1.0). The color shifts towards orange and then reddish-purple in the bottom rows (`facts`, `neg_facts`), indicating lower accuracy. The `CCS` column generally shows more orange/red cells (lower accuracy) and higher standard deviations compared to the other columns.
* **Method Performance Trend:** `TTPD` and `LR` columns are predominantly yellow, suggesting consistently high performance. `MM` is also mostly yellow but shows a significant drop (orange cell) for `neg_sp_en_trans`. `CCS` has the most variability and the lowest overall accuracy values.
### Key Observations
1. **High-Performance Clusters:** The tasks `cities`, `neg_cities`, `animal_class`, and `neg_animal_class` achieve near-perfect accuracy (97-100%) across most methods, with very low standard deviations.
2. **Method Comparison:**
* **LR** achieves the highest single score (100 ± 0 on `cities` and `neg_cities`) and is consistently at or near the top.
* **TTPD** is very stable and high-performing, with its lowest score being 75 ± 0 on `neg_facts`.
* **MM** performs well on most tasks but has a notable weakness on `neg_sp_en_trans` (76 ± 5).
* **CCS** is the weakest performer overall, with the lowest scores in 7 out of 12 tasks and the highest standard deviations (e.g., 89 ± 19, 83 ± 20), indicating less reliable results.
3. **Task Difficulty:** The `neg_facts` task appears to be the most challenging, yielding the lowest scores for all methods (71-81%). The `facts` task is also relatively difficult.
4. **"Neg" Task Pattern:** For most categories, the "neg_" (likely negated or contrastive) version of the task shows a slight decrease in accuracy compared to its positive counterpart, with the exception of `neg_cities` and `neg_inventors` (for MM).
### Interpretation
This heatmap provides a comparative benchmark of four classification methods. The data suggests that **LR and TTPD are the most robust and accurate methods** across this diverse set of tasks, maintaining high performance with low variance. The **CCS method appears significantly less reliable**, characterized by lower accuracy and high uncertainty (large standard deviations), which may indicate it is sensitive to the specific dataset or is a less suitable model for these tasks.
The stark difference in performance between task categories (e.g., `cities` vs. `neg_facts`) implies that the underlying datasets vary greatly in difficulty or that the methods have inherent biases towards certain types of problems. The consistent, slight performance drop on "neg_" tasks could point to a systematic challenge in handling negation or contrastive examples for these models. The outlier performance of MM on `neg_sp_en_trans` warrants further investigation to understand why this specific method-task combination underperforms.
In summary, the chart effectively communicates that method choice is critical, with LR/TTPD being preferable for these tasks, while also highlighting specific task difficulties and potential model weaknesses.