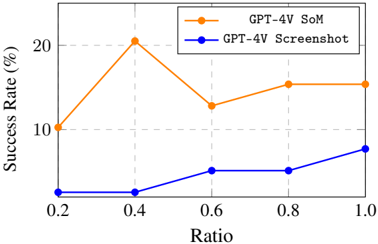
## Line Graph: Success Rate vs Ratio for GPT-4V Models
### Overview
The image depicts a line graph comparing the success rates of two GPT-4V variants ("GPT-4V SoM" and "GPT-4V Screenshot") across varying ratios (0.2 to 1.0). The y-axis represents success rate in percentage (0–20%), while the x-axis represents ratio values. Two distinct trends are observed: one for "GPT-4V SoM" (orange line) and one for "GPT-4V Screenshot" (blue line).
### Components/Axes
- **X-axis (Ratio)**: Labeled "Ratio" with markers at 0.2, 0.4, 0.6, 0.8, and 1.0.
- **Y-axis (Success Rate)**: Labeled "Success Rate (%)" with markers at 0, 10, and 20.
- **Legend**: Located in the top-right corner, with orange representing "GPT-4V SoM" and blue representing "GPT-4V Screenshot".
- **Lines**:
- Orange line (GPT-4V SoM) with circular markers.
- Blue line (GPT-4V Screenshot) with circular markers.
### Detailed Analysis
#### GPT-4V SoM (Orange Line)
- **0.2**: Starts at ~10%.
- **0.4**: Peaks sharply at ~20%.
- **0.6**: Drops to ~12%.
- **0.8**: Rises to ~15%.
- **1.0**: Remains stable at ~15%.
#### GPT-4V Screenshot (Blue Line)
- **0.2**: Starts at ~0%.
- **0.4**: Remains flat at ~0%.
- **0.6**: Increases to ~5%.
- **0.8**: Rises to ~5%.
- **1.0**: Increases to ~8%.
### Key Observations
1. **GPT-4V SoM** exhibits a bimodal trend: a sharp peak at 0.4 followed by a decline and partial recovery.
2. **GPT-4V Screenshot** shows minimal activity until 0.6, then a gradual but steady increase.
3. Both lines converge at 1.0, but "GPT-4V SoM" maintains a higher success rate (~15%) compared to "GPT-4V Screenshot" (~8%).
### Interpretation
The data suggests that "GPT-4V SoM" performs significantly better at lower ratios (0.2–0.4), achieving near-peak success at 0.4. However, its performance declines at 0.6 before stabilizing. In contrast, "GPT-4V Screenshot" demonstrates a delayed but consistent improvement as the ratio increases, though it never surpasses the baseline of "GPT-4V SoM". The divergence at 0.4 implies that the "SoM" variant may leverage ratio-dependent mechanisms more effectively, while the "Screenshot" variant’s delayed response could indicate reliance on higher ratios for contextual understanding. The flat performance of "GPT-4V Screenshot" at 0.2–0.4 highlights potential limitations in low-ratio scenarios.