## Diagram: Transformer Architecture
### Overview
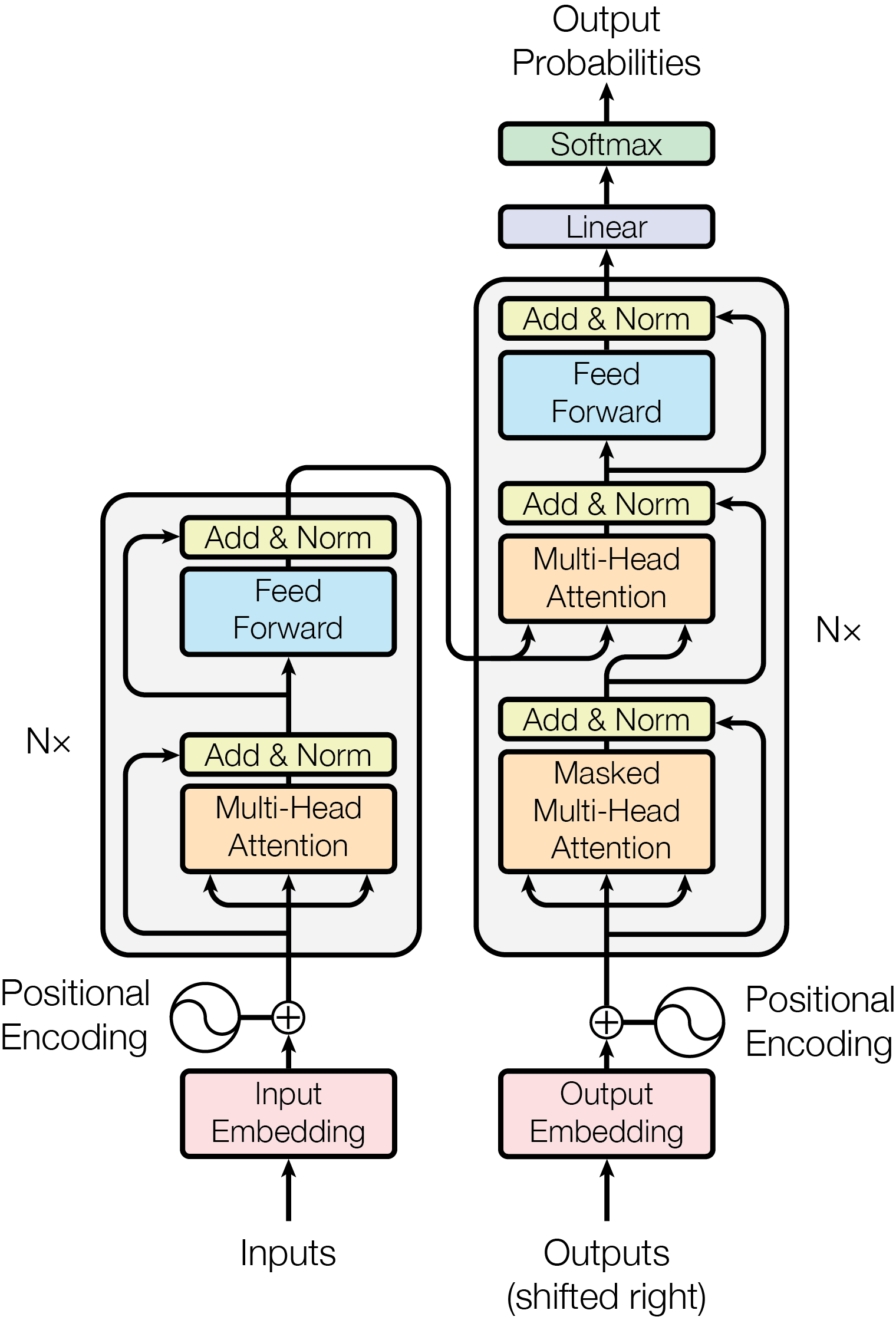
The image is a diagram illustrating the architecture of a Transformer model, a neural network architecture widely used in natural language processing. It shows the flow of data through the encoder (left) and decoder (right) components, highlighting key layers like multi-head attention, feed-forward networks, and normalization steps.
### Components/Axes
* **Input:** The diagram starts with "Inputs" at the bottom, feeding into an "Input Embedding" block (pink).
* **Positional Encoding:** A "Positional Encoding" block is added to the input embedding.
* **Encoder Stack:** The left side represents the encoder, which consists of N<sub>x</sub> (N subscript x) layers. Each layer contains:
* "Multi-Head Attention" (orange)
* "Add & Norm" (yellow)
* "Feed Forward" (blue)
* "Add & Norm" (yellow)
* **Decoder Stack:** The right side represents the decoder, which also consists of N<sub>x</sub> (N subscript x) layers. Each layer contains:
* "Masked Multi-Head Attention" (orange)
* "Add & Norm" (yellow)
* "Multi-Head Attention" (orange)
* "Add & Norm" (yellow)
* "Feed Forward" (blue)
* "Add & Norm" (yellow)
* **Output:** The output of the decoder goes through a "Linear" layer (purple) and a "Softmax" layer (green) to produce "Output Probabilities" at the top.
* **Outputs (shifted right):** The bottom right shows "Outputs (shifted right)" feeding into an "Output Embedding" block (pink), with "Positional Encoding" added.
### Detailed Analysis or ### Content Details
* **Encoder:** The input embeddings are combined with positional encodings. This combined representation is then passed through a stack of N<sub>x</sub> encoder layers. Each encoder layer consists of a multi-head attention mechanism followed by an add & norm layer, and then a feed-forward network followed by another add & norm layer. The output of each encoder layer is fed into the next encoder layer in the stack.
* **Decoder:** The decoder mirrors the encoder in its stacked architecture. The input to the decoder is the output embedding combined with positional encoding, and the output of the encoder stack. Each decoder layer contains a masked multi-head attention mechanism followed by an add & norm layer, a multi-head attention mechanism followed by an add & norm layer, and then a feed-forward network followed by another add & norm layer. The masked multi-head attention prevents the decoder from attending to future tokens. The output of the final decoder layer is passed through a linear layer and then a softmax layer to produce the output probabilities.
* **Residual Connections and Normalization:** "Add & Norm" blocks indicate residual connections (adding the input of a layer to its output) and layer normalization.
* **Arrows:** Arrows indicate the direction of data flow.
### Key Observations
* The diagram highlights the key components of the Transformer architecture: input embeddings, positional encoding, multi-head attention, feed-forward networks, residual connections, and layer normalization.
* The encoder and decoder have a similar structure, with stacked layers of attention and feed-forward networks.
* The "Masked Multi-Head Attention" in the decoder is crucial for autoregressive generation, where the model predicts the next token based on the previously generated tokens.
* The N<sub>x</sub> notation indicates that the encoder and decoder can have multiple layers, allowing the model to learn complex relationships in the data.
### Interpretation
The diagram illustrates the Transformer architecture, which is a powerful and versatile neural network architecture that has achieved state-of-the-art results in a variety of natural language processing tasks. The use of multi-head attention allows the model to attend to different parts of the input sequence, while the residual connections and layer normalization help to stabilize training and improve performance. The encoder-decoder structure allows the model to handle sequence-to-sequence tasks, such as machine translation and text summarization. The diagram provides a clear and concise overview of the Transformer architecture, making it a valuable resource for anyone interested in learning more about this important topic.