\n
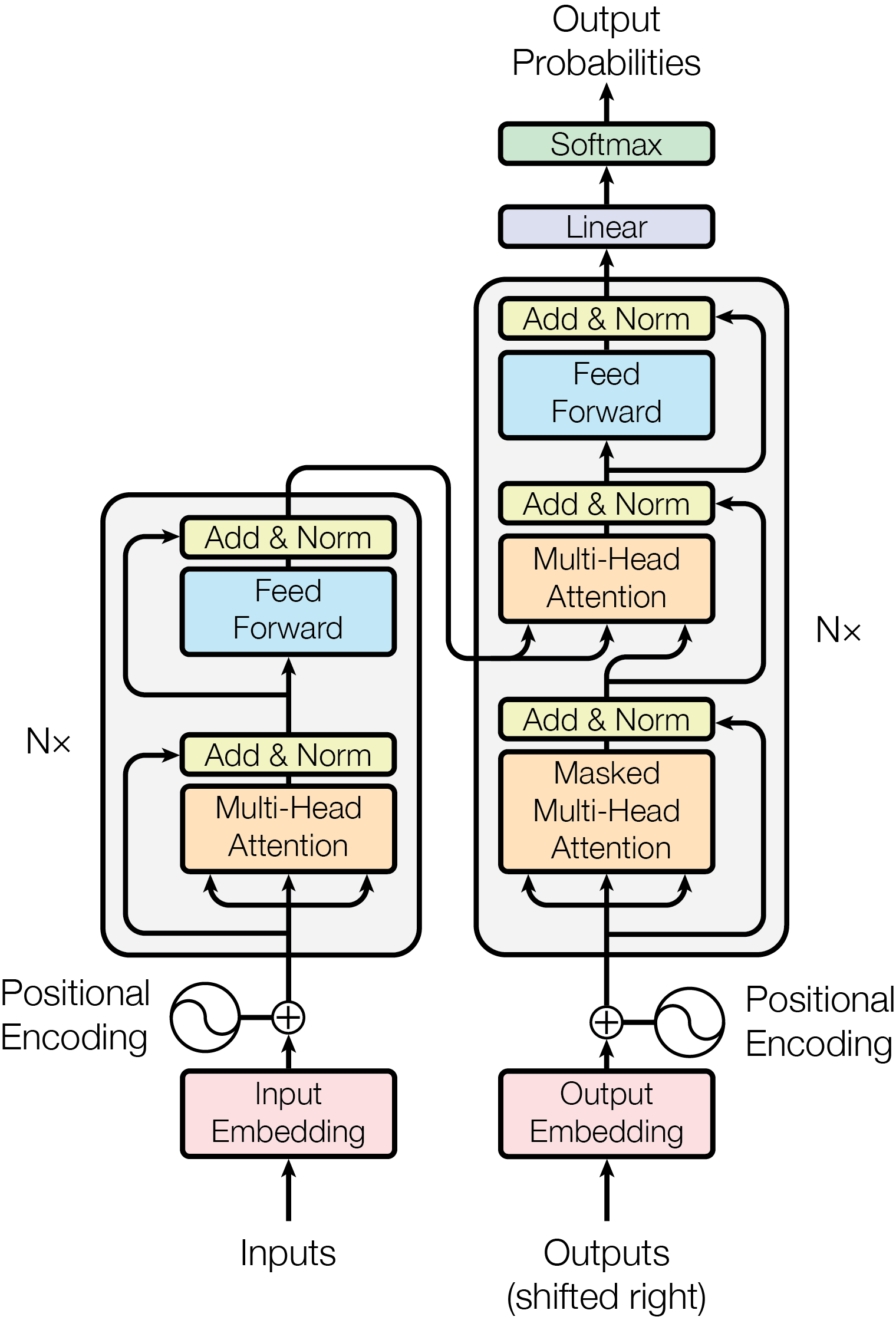
## Diagram: Transformer Model Architecture
### Overview
The image depicts the architecture of a Transformer model, a deep learning model commonly used in natural language processing. The diagram illustrates the encoder and decoder components, highlighting the key layers and connections within each. It shows the flow of data through the model, from input embeddings to output probabilities.
### Components/Axes
The diagram consists of two main stacks, labeled "Nx" on the right side, representing multiple layers. The left stack represents the encoder, and the right stack represents the decoder. Key components include:
* **Inputs:** The initial data fed into the encoder.
* **Outputs (shifted right):** The output of the decoder, shifted one position to the right for autoregressive prediction.
* **Positional Encoding:** A method to add information about the position of tokens in the sequence.
* **Input Embedding:** Converts input tokens into vector representations.
* **Output Embedding:** Converts output tokens into vector representations.
* **Masked Multi-Head Attention:** Attention mechanism used in the decoder to prevent looking ahead at future tokens.
* **Multi-Head Attention:** Attention mechanism used in both encoder and decoder to weigh the importance of different parts of the input sequence.
* **Add & Norm:** Residual connections and layer normalization.
* **Feed Forward:** Fully connected feedforward network.
* **Linear:** Linear transformation layer.
* **Softmax:** Activation function to produce probability distribution over output tokens.
* **Output Probabilities:** The final output of the model, representing the predicted probabilities for each token.
### Detailed Analysis or Content Details
The diagram shows a clear flow of information:
**Encoder (Left Stack):**
1. **Inputs** are passed through **Input Embedding**.
2. **Positional Encoding** is added to the embedded inputs.
3. The combined signal goes through multiple layers (Nx) of:
* **Add & Norm**
* **Multi-Head Attention**
* **Add & Norm**
* **Feed Forward**
**Decoder (Right Stack):**
1. **Outputs (shifted right)** are passed through **Output Embedding**.
2. **Positional Encoding** is added to the embedded outputs.
3. The combined signal goes through multiple layers (Nx) of:
* **Add & Norm**
* **Masked Multi-Head Attention**
* **Add & Norm**
* **Feed Forward**
4. The output of the final decoder layer is passed through:
* **Add & Norm**
* **Linear**
* **Softmax** to produce **Output Probabilities**.
The connections between the encoder and decoder are represented by arrows, indicating that the output of the encoder is used as input to the decoder's attention mechanisms. The "Nx" label indicates that the encoder and decoder stacks are repeated multiple times, creating a deep network.
### Key Observations
* The diagram emphasizes the use of attention mechanisms as a core component of the Transformer architecture.
* The residual connections ("Add & Norm") are present in every layer, facilitating gradient flow during training.
* The decoder uses a "Masked Multi-Head Attention" layer, which is crucial for autoregressive sequence generation.
* The positional encoding is added to both the input and output embeddings, indicating its importance in capturing sequential information.
### Interpretation
The diagram illustrates the key architectural elements of a Transformer model, which has revolutionized the field of natural language processing. The use of attention mechanisms allows the model to focus on relevant parts of the input sequence, while the residual connections and layer normalization improve training stability. The encoder-decoder structure enables the model to map input sequences to output sequences, making it suitable for tasks such as machine translation, text summarization, and question answering. The "Nx" notation highlights the depth of the model, which is crucial for capturing complex relationships in the data. The diagram provides a high-level overview of the Transformer architecture, without delving into the specific mathematical details of each component. It is a visual representation of a powerful and versatile deep learning model.