# Technical Document Extraction: Transformer Model Architecture
## Diagram Overview
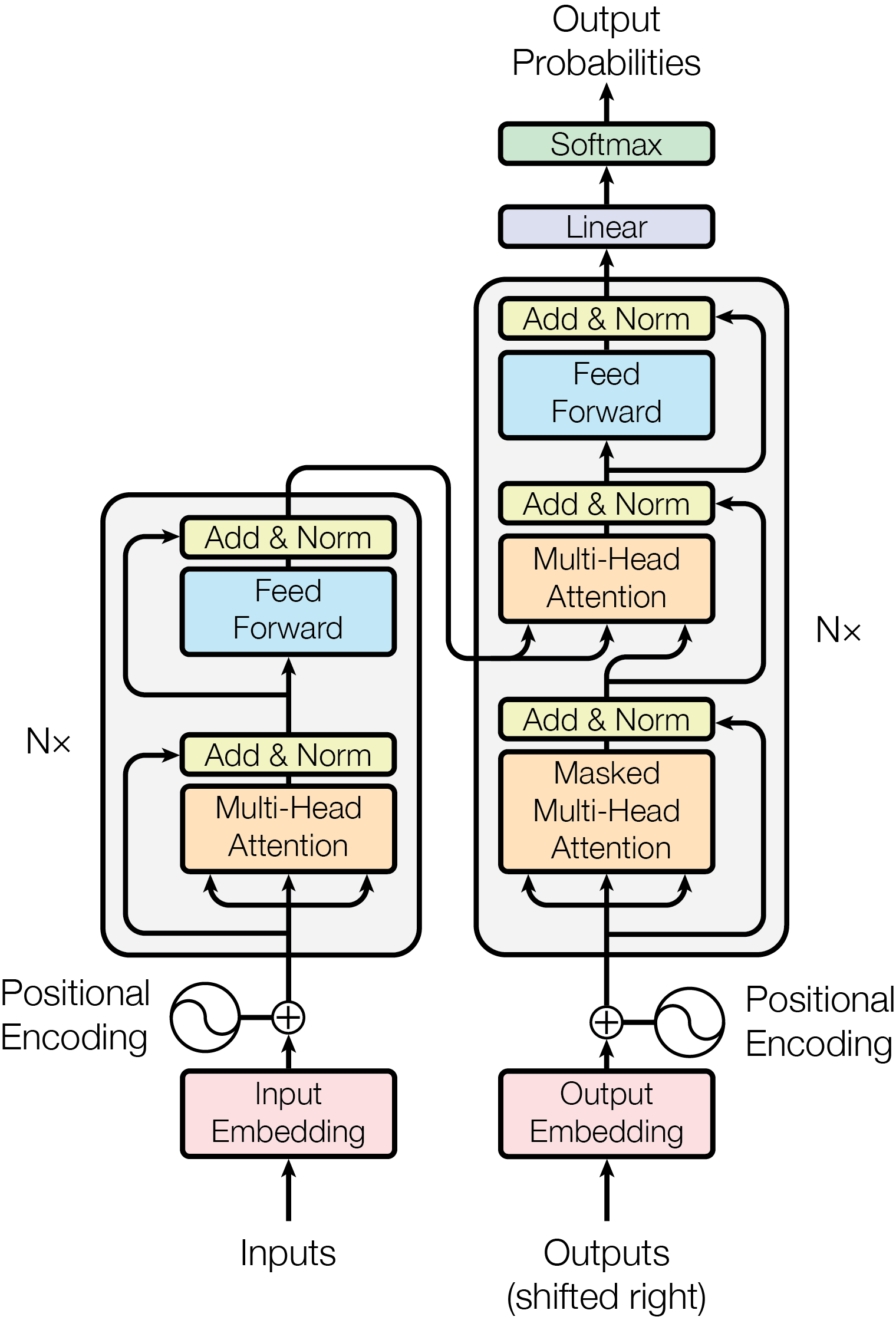
This diagram illustrates the architecture of a Transformer model, showing the flow of data from inputs to output probabilities. The model includes encoder and decoder components with multiple layers, attention mechanisms, and normalization steps.
---
### Key Components and Flow
1. **Input Section**
- **Inputs**: Raw data fed into the model.
- **Input Embedding**: Converts input tokens into dense vectors.
- **Positional Encoding**: Adds positional information to embeddings (swirl symbol indicates sinusoidal encoding).
2. **Encoder Block (Repeated N× times)**
- **Masked Multi-Head Attention**: Self-attention mechanism with masking to prevent look-ahead during training.
- **Add & Norm**: Residual connection followed by layer normalization.
- **Feed Forward**: Position-wise feed-forward network (not explicitly labeled but implied by flow).
3. **Decoder Block (Repeated N× times)**
- **Multi-Head Attention**: Self-attention mechanism for decoder outputs.
- **Add & Norm**: Residual connection followed by layer normalization.
- **Multi-Head Attention (Encoder-Decoder)**: Attention over encoder outputs.
- **Add & Norm**: Residual connection followed by layer normalization.
- **Feed Forward**: Position-wise feed-forward network.
4. **Output Section**
- **Output Embedding**: Converts decoder outputs into token-specific embeddings.
- **Positional Encoding**: Adds positional information to output embeddings.
- **Linear Layer**: Projects embeddings to vocabulary size.
- **Softmax**: Normalizes outputs to probability distribution over tokens.
---
### Spatial Grounding and Flow
- **Input Path**:
- Inputs → Input Embedding → Positional Encoding → Encoder Blocks (N×) → Output Embedding → Positional Encoding → Decoder Blocks (N×) → Linear → Softmax → Output Probabilities.
- **Residual Connections**:
- Add & Norm blocks appear after each attention/feed-forward layer in both encoder and decoder.
- **Masking**:
- Applied only in the encoder's Masked Multi-Head Attention to prevent future token leakage.
---
### Notes
- **N×**: Indicates the number of repeated layers in encoder/decoder stacks (exact value not specified).
- **Output Shift**: Decoder outputs are shifted right by one token to align with target sequences during training.
- **No Data Table**: The diagram focuses on architectural components rather than numerical data.
---
### Diagram Structure
1. **Header**: Title "Output Probabilities" at the top.
2. **Main Chart**:
- Left side: Encoder components.
- Right side: Decoder components.
- Central flow: Connections between encoder and decoder attention.
3. **Footer**: Output Probabilities at the top, Inputs at the bottom.
---
### Transcribed Text
- Labels: Inputs, Outputs (shifted right), Input Embedding, Output Embedding, Positional Encoding, Add & Norm, Feed Forward, Multi-Head Attention, Masked Multi-Head Attention, Linear, Softmax.
- Symbols: Swirl (Positional Encoding), Plus sign (addition), Arrows (data flow).
---
### Conclusion
This diagram provides a comprehensive view of a Transformer model's architecture, emphasizing the interplay between attention mechanisms, normalization, and positional encoding. The encoder-decoder structure with masked attention ensures autoregressive generation while maintaining context awareness.