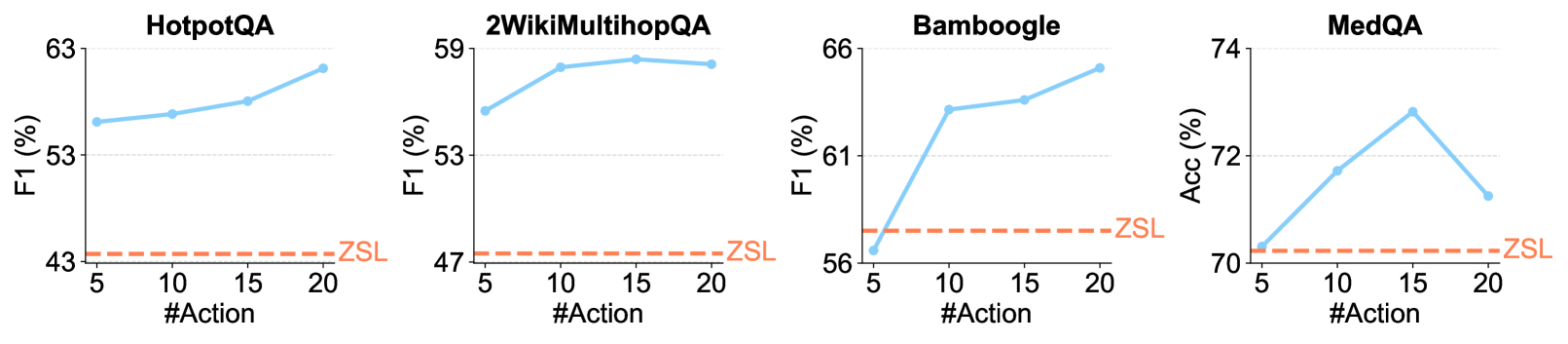
## Line Graphs: F1 Score vs. #Action Across Datasets
### Overview
The image contains four line graphs comparing the F1 score (y-axis) against the number of actions (#Action, x-axis) for different question-answering datasets: **HotpotQA**, **2WikiMultihopQA**, **Bamboogle**, and **MedQA**. A dashed red line labeled **ZSL** (Zero-Shot Learning) is present in all graphs, serving as a baseline.
### Components/Axes
- **X-axis**: Labeled `#Action`, with values at 5, 10, 15, and 20.
- **Y-axis**: Labeled `F1 (%)`, with ranges varying by dataset:
- HotpotQA: 53–63%
- 2WikiMultihopQA: 47–59%
- Bamboogle: 56–66%
- MedQA: 70–74%
- **Legend**: A dashed red line labeled **ZSL** appears at the bottom of each graph.
### Detailed Analysis
#### HotpotQA
- **Trend**: F1 score increases steadily from ~54% at 5 actions to ~58% at 20 actions.
- **ZSL Baseline**: Remains flat at ~43% across all #Action values.
#### 2WikiMultihopQA
- **Trend**: F1 score rises from ~54% at 5 actions to ~58% at 15 actions, then slightly declines to ~57% at 20 actions.
- **ZSL Baseline**: Flat at ~47%.
#### Bamboogle
- **Trend**: Sharp increase from ~56% at 5 actions to ~65% at 15 actions, followed by a drop to ~63% at 20 actions.
- **ZSL Baseline**: Flat at ~56%.
#### MedQA
- **Trend**: F1 score rises from ~70% at 5 actions to ~73% at 15 actions, then declines to ~71% at 20 actions.
- **ZSL Baseline**: Flat at ~70%.
### Key Observations
1. **Performance Trends**:
- All datasets show improved F1 scores with increasing #Action, except **Bamboogle** and **MedQA**, which peak at 15 actions before declining.
- **ZSL** consistently underperforms compared to the main models across all datasets.
2. **Anomalies**:
- **Bamboogle** exhibits the steepest rise (56% → 65%) but also the sharpest drop at 20 actions.
- **MedQA** has the highest absolute F1 scores but shows a notable decline after 15 actions.
### Interpretation
- **Action Efficiency**: The data suggests that increasing the number of actions generally improves performance, but diminishing returns or overfitting may occur beyond a threshold (e.g., 15 actions for Bamboogle and MedQA).
- **ZSL Limitations**: The flat ZSL line indicates that zero-shot learning struggles to adapt to these datasets, highlighting the need for task-specific tuning.
- **Dataset Complexity**: **MedQA**’s higher baseline F1 scores suggest it may involve simpler or more structured tasks compared to others like **HotpotQA** or **2WikiMultihopQA**.
*Note: All values are approximate, derived from visual inspection of the graphs.*