\n
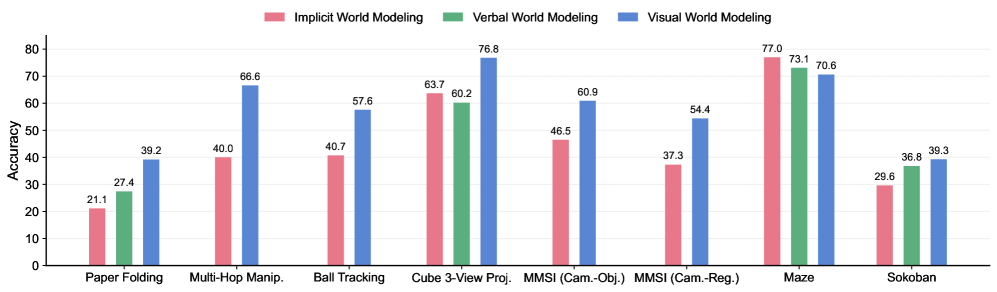
## Bar Chart: Accuracy Comparison of World Modeling Techniques
### Overview
This bar chart compares the accuracy of three world modeling techniques – Implicit, Verbal, and Visual – across seven different tasks. Accuracy is measured on the y-axis, ranging from 0 to 80, while the x-axis represents the different tasks: Paper Folding, Multi-Hop Manipulation, Ball Tracking, Cube 3-View Projection, MMSI (Cam.-Obj.), MMSI (Cam.-Reg.), Maze, and Sokoban.
### Components/Axes
* **X-axis:** Task Name (Categorical) - Paper Folding, Multi-Hop Manip., Ball Tracking, Cube 3-View Proj., MMSI (Cam.-Obj.), MMSI (Cam.-Reg.), Maze, Sokoban.
* **Y-axis:** Accuracy (Numerical) - Scale from 0 to 80.
* **Legend:**
* Implicit World Modeling (Pink/Reddish)
* Verbal World Modeling (Green)
* Visual World Modeling (Blue)
* **Chart Title:** Not explicitly present, but the chart represents an accuracy comparison.
### Detailed Analysis
The chart consists of grouped bar plots for each task, with three bars representing the accuracy of each world modeling technique.
* **Paper Folding:**
* Implicit: Approximately 21.1
* Verbal: Approximately 27.4
* Visual: Approximately 39.2
* **Multi-Hop Manip.:**
* Implicit: Approximately 40.0
* Verbal: Not present
* Visual: Approximately 66.6
* **Ball Tracking:**
* Implicit: Approximately 40.7
* Verbal: Not present
* Visual: Approximately 57.6
* **Cube 3-View Proj.:**
* Implicit: Approximately 60.2
* Verbal: Approximately 63.7
* Visual: Approximately 76.8
* **MMSI (Cam.-Obj.):**
* Implicit: Approximately 46.5
* Verbal: Approximately 37.3
* Visual: Approximately 60.9
* **MMSI (Cam.-Reg.):**
* Implicit: Approximately 54.4
* Verbal: Not present
* Visual: Not present
* **Maze:**
* Implicit: Approximately 70.6
* Verbal: Approximately 73.1
* Visual: Approximately 77.0
* **Sokoban:**
* Implicit: Approximately 29.6
* Verbal: Approximately 36.8
* Visual: Approximately 39.3
**Trends:**
* **Visual World Modeling** generally performs the best across most tasks, often achieving the highest accuracy. It shows a generally upward trend across the tasks.
* **Implicit World Modeling** shows variable performance, with some tasks showing relatively low accuracy and others showing competitive results.
* **Verbal World Modeling** is not present for all tasks, and its performance varies.
### Key Observations
* Visual World Modeling consistently outperforms the other two methods on most tasks.
* The largest performance gap between the methods is observed in the "Maze" task.
* The "MMSI (Cam.-Reg.)" task only shows data for Implicit World Modeling.
* The "Multi-Hop Manip." and "Ball Tracking" tasks do not have data for Verbal World Modeling.
### Interpretation
The data suggests that Visual World Modeling is the most effective technique for these tasks, consistently achieving higher accuracy than Implicit and Verbal World Modeling. This could be due to the ability of visual models to directly process and understand visual information, which is crucial for tasks involving spatial reasoning and object manipulation. The absence of data for Verbal World Modeling in some tasks suggests it may not be applicable or effective for those specific scenarios. The varying performance of Implicit World Modeling indicates its effectiveness is highly task-dependent. The consistent high performance of Visual World Modeling across a range of tasks suggests its robustness and generalizability. The lack of data for certain combinations (e.g., Verbal on Multi-Hop Manip.) could indicate limitations in applying those modeling techniques to those specific problems, or simply a lack of experimentation. The chart highlights the importance of selecting the appropriate world modeling technique based on the specific requirements of the task.