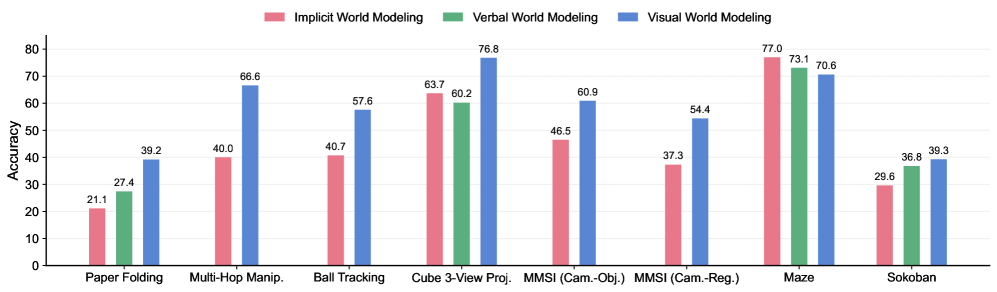
## Grouped Bar Chart: World Modeling Accuracy Across Tasks
### Overview
The image displays a grouped bar chart comparing the accuracy of three different world modeling approaches—Implicit, Verbal, and Visual—across eight distinct tasks. The chart is designed to show performance differences, with each task cluster containing up to three colored bars representing the modeling types.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:** Labeled "Accuracy". The scale runs from 0 to 80, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50, 60, 70, 80).
* **X-Axis:** Lists eight task categories. From left to right:
1. Paper Folding
2. Multi-Hop Manip. (presumably "Manipulation")
3. Ball Tracking
4. Cube 3-View Proj. (presumably "Projection")
5. MMSI (Cam.-Obj.) (presumably "Camera-Object")
6. MMSI (Cam.-Reg.) (presumably "Camera-Region")
7. Maze
8. Sokoban
* **Legend:** Positioned at the top center of the chart. It defines the three data series:
* **Pink Bar:** Implicit World Modeling
* **Green Bar:** Verbal World Modeling
* **Blue Bar:** Visual World Modeling
* **Data Labels:** Each bar has its exact accuracy value printed directly above it.
### Detailed Analysis
Below is the extracted data for each task, following the order of bars (Pink, Green, Blue) as defined by the legend.
1. **Paper Folding:**
* Implicit (Pink): 21.1
* Verbal (Green): 27.4
* Visual (Blue): 39.2
* *Trend:* Accuracy increases sequentially from Implicit to Verbal to Visual.
2. **Multi-Hop Manip.:**
* Implicit (Pink): 40.0
* Verbal (Green): 40.7
* Visual (Blue): 66.6
* *Trend:* Implicit and Verbal are nearly equal, while Visual shows a significant jump in accuracy.
3. **Ball Tracking:**
* Implicit (Pink): 40.7
* Verbal (Green): **No bar present.**
* Visual (Blue): 57.6
* *Trend:* Visual outperforms Implicit. Data for Verbal World Modeling is absent for this task.
4. **Cube 3-View Proj.:**
* Implicit (Pink): 63.7
* Verbal (Green): 60.2
* Visual (Blue): 76.8
* *Trend:* Visual is highest, followed by Implicit, then Verbal.
5. **MMSI (Cam.-Obj.):**
* Implicit (Pink): 46.5
* Verbal (Green): **No bar present.**
* Visual (Blue): 60.9
* *Trend:* Visual significantly outperforms Implicit. Data for Verbal is absent.
6. **MMSI (Cam.-Reg.):**
* Implicit (Pink): 37.3
* Verbal (Green): **No bar present.**
* Visual (Blue): 54.4
* *Trend:* Visual significantly outperforms Implicit. Data for Verbal is absent.
7. **Maze:**
* Implicit (Pink): 77.0
* Verbal (Green): 73.1
* Visual (Blue): 70.6
* *Trend:* This is the only task where accuracy *decreases* across the sequence, with Implicit performing best.
8. **Sokoban:**
* Implicit (Pink): 29.6
* Verbal (Green): 36.8
* Visual (Blue): 39.3
* *Trend:* Accuracy increases sequentially from Implicit to Verbal to Visual.
### Key Observations
* **Performance Leader:** Visual World Modeling (blue bars) achieves the highest accuracy in 6 out of the 8 tasks (Paper Folding, Multi-Hop Manip., Ball Tracking, Cube 3-View Proj., MMSI (Cam.-Obj.), MMSI (Cam.-Reg.), and Sokoban).
* **Notable Exception:** The **Maze** task is a clear outlier. Here, Implicit World Modeling (77.0) outperforms both Verbal (73.1) and Visual (70.6). This is the only task where the pink bar is the tallest.
* **Missing Data:** Verbal World Modeling (green bars) has no recorded accuracy for three tasks: Ball Tracking, MMSI (Cam.-Obj.), and MMSI (Cam.-Reg.).
* **Highest & Lowest Scores:** The highest accuracy on the chart is 77.0 (Implicit, Maze). The lowest accuracy is 21.1 (Implicit, Paper Folding).
* **Task Difficulty:** Tasks like Paper Folding and Sokoban show relatively low accuracy across all models (<40), suggesting they are more challenging. In contrast, Maze and Cube 3-View Proj. show high accuracy (>60) for all models that attempted them.
### Interpretation
The data suggests a strong, general advantage for **Visual World Modeling** across a variety of tasks involving spatial reasoning, object manipulation, and projection. Its consistent high performance indicates that a visual representation is highly effective for modeling these types of physical or geometric environments.
The **Maze** task's inverted trend is the most significant finding. It implies that for complex navigation and pathfinding within a constrained environment, an **Implicit** modeling approach (perhaps learning a latent policy or value function) is superior to explicit visual or verbal reasoning. This could be because mazes require integrating long-term consequences of actions, which implicit models might capture more efficiently.
The absence of data for **Verbal World Modeling** in several tasks (Ball Tracking, MMSI variants) may indicate that a verbal or language-based representation was deemed unsuitable or was not tested for those specific, potentially highly dynamic or visual-spatial, tasks. Where it was tested, it generally performed as an intermediate between Implicit and Visual, except in the Maze task.
In summary, the chart demonstrates that the optimal world modeling strategy is **task-dependent**. While visual models are broadly robust, specialized tasks like maze navigation may favor implicit learning. The results could guide the selection or hybridization of modeling approaches for artificial intelligence systems based on the problem domain.