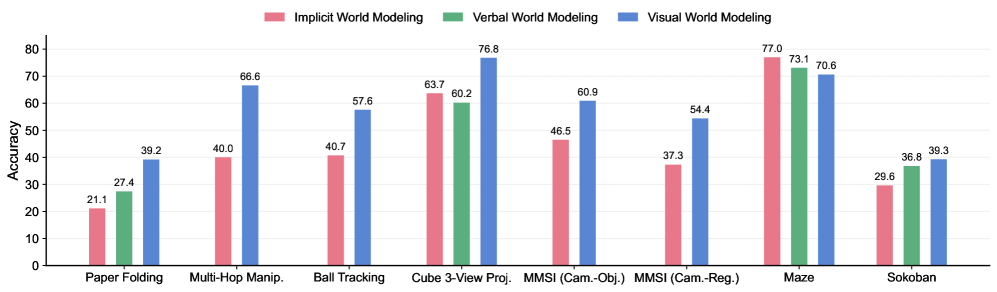
## Bar Chart: Accuracy of Different World Modeling Approaches Across Tasks
### Overview
The chart compares the accuracy of three world modeling approaches (Implicit, Verbal, Visual) across nine cognitive tasks. Each task has three grouped bars representing the three modeling types, with accuracy percentages ranging from 0-80% on the y-axis.
### Components/Axes
- **X-axis (Tasks)**:
- Paper Folding
- Multi-Hop Manip.
- Ball Tracking
- Cube 3-View Proj.
- MMSI (Cam.-Obj.)
- MMSI (Cam.-Reg.)
- Maze
- Sokoban
- **Y-axis (Accuracy)**: 0-80% scale
- **Legend**:
- Pink = Implicit World Modeling
- Green = Verbal World Modeling
- Blue = Visual World Modeling
- **Bar Colors**:
- Implicit (pink) consistently shortest bars
- Verbal (green) mid-range
- Visual (blue) tallest bars in most cases
### Detailed Analysis
1. **Paper Folding**:
- Implicit: 21.1%
- Verbal: 27.4%
- Visual: 39.2%
2. **Multi-Hop Manip.**:
- Implicit: 40.0%
- Verbal: N/A
- Visual: 66.6%
3. **Ball Tracking**:
- Implicit: 40.7%
- Verbal: N/A
- Visual: 57.6%
4. **Cube 3-View Proj.**:
- Implicit: 63.7%
- Verbal: 60.2%
- Visual: 76.8%
5. **MMSI (Cam.-Obj.)**:
- Implicit: 46.5%
- Verbal: N/A
- Visual: 60.9%
6. **MMSI (Cam.-Reg.)**:
- Implicit: 37.3%
- Verbal: N/A
- Visual: 54.4%
7. **Maze**:
- Implicit: 77.0%
- Verbal: 73.1%
- Visual: 70.6%
8. **Sokoban**:
- Implicit: 29.6%
- Verbal: 36.8%
- Visual: 39.3%
### Key Observations
- **Visual World Modeling Dominance**: Blue bars (Visual) outperform others in 7/8 tasks, with the largest margin in Multi-Hop Manip. (66.6%).
- **Implicit Underperformance**: Pink bars (Implicit) are lowest in 6/8 tasks, with the worst result in Paper Folding (21.1%).
- **Maze Exception**: Implicit achieves highest accuracy (77.0%) in Maze, surpassing Verbal (73.1%) and Visual (70.6%).
- **Sokoban Parity**: Verbal (36.8%) and Visual (39.3%) show minimal difference, both outperforming Implicit (29.6%).
### Interpretation
The data suggests **Visual World Modeling** is generally most effective across diverse cognitive tasks, particularly in complex spatial reasoning (Multi-Hop Manip., Ball Tracking). **Implicit Modeling** struggles in most scenarios but excels in Maze navigation, potentially indicating task-specific advantages (e.g., low-level pattern recognition). The consistent gap between Implicit and other approaches highlights opportunities for improving implicit representation learning. The Maze outlier warrants investigation into whether task characteristics (e.g., rule-based navigation) favor implicit processing. Sokoban's near-parity between Verbal and Visual suggests both may leverage different cognitive mechanisms for puzzle-solving.