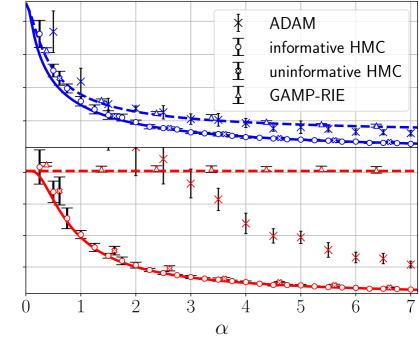
## Chart: Convergence Rate Comparison
### Overview
The image presents a line chart comparing the convergence rates of four different Markov Chain Monte Carlo (MCMC) methods: ADAM, informative Hamiltonian Monte Carlo (HMC), uninformative HMC, and Gaussian Adaptive Metropolis-Hastings with Riemannian Exponential (GAMP-RIE). The chart plots a metric representing convergence (likely error or some measure of distance to the true parameter values) against a parameter denoted by α (alpha). Error bars are included for each data series, indicating the uncertainty or variance in the convergence metric.
### Components/Axes
* **X-axis:** Labeled "α" (alpha). The scale ranges from approximately 0 to 7, with tick marks at integer values.
* **Y-axis:** The Y-axis is not explicitly labeled, but represents a convergence metric. The scale ranges from approximately 0 to 1.5.
* **Legend:** Located in the top-right corner of the chart. It identifies the four data series with corresponding colors and markers:
* ADAM (Black, asterisk)
* informative HMC (Dark Blue, square with error bar)
* uninformative HMC (Dark Orange, triangle with error bar)
* GAMP-RIE (Light Blue, circle with error bar)
* **Grid:** A light gray grid is present, aiding in the reading of values.
### Detailed Analysis
Here's a breakdown of each data series, including trend descriptions and approximate data points.
* **ADAM (Black Asterisk):** The line slopes sharply downward from α = 0 to approximately α = 1.5, then flattens out, approaching a value of approximately 0.15-0.2.
* α = 0: ~1.2
* α = 1: ~0.6
* α = 2: ~0.3
* α = 3: ~0.22
* α = 4: ~0.18
* α = 5: ~0.16
* α = 6: ~0.15
* α = 7: ~0.15
* **informative HMC (Dark Blue Square):** The line starts at approximately 0.8 at α = 0, decreases rapidly to around 0.2 at α = 1, and then plateaus around 0.15-0.2 for α > 2.
* α = 0: ~0.8
* α = 1: ~0.2
* α = 2: ~0.18
* α = 3: ~0.17
* α = 4: ~0.16
* α = 5: ~0.16
* α = 6: ~0.16
* α = 7: ~0.16
* **uninformative HMC (Dark Orange Triangle):** This line exhibits a slower initial decrease compared to ADAM and informative HMC. It starts at approximately 0.6 at α = 0, decreases to around 0.2 at α = 3, and then levels off around 0.1-0.15. The error bars are notably larger for this method.
* α = 0: ~0.6
* α = 1: ~0.4
* α = 2: ~0.3
* α = 3: ~0.2
* α = 4: ~0.15
* α = 5: ~0.13
* α = 6: ~0.12
* α = 7: ~0.12
* **GAMP-RIE (Light Blue Circle):** This line shows a similar trend to informative HMC, starting at approximately 0.7 at α = 0, decreasing to around 0.2 at α = 1, and then plateauing around 0.15-0.2.
* α = 0: ~0.7
* α = 1: ~0.2
* α = 2: ~0.18
* α = 3: ~0.17
* α = 4: ~0.16
* α = 5: ~0.16
* α = 6: ~0.16
* α = 7: ~0.16
### Key Observations
* ADAM exhibits the fastest initial convergence, but plateaus relatively quickly.
* informative HMC and GAMP-RIE show similar convergence behavior, reaching a stable level around α = 2.
* uninformative HMC converges more slowly and has larger error bars, indicating greater uncertainty in its convergence.
* All methods appear to converge to a similar level as α increases.
### Interpretation
The chart demonstrates the convergence properties of different MCMC algorithms as a function of the parameter α. The faster initial convergence of ADAM suggests it might be suitable for quickly exploring the parameter space. However, its plateauing behavior indicates it may not achieve the same level of accuracy as informative HMC or GAMP-RIE in the long run. The slower convergence and larger uncertainty of uninformative HMC suggest it may require more iterations to achieve reliable results. The similarity between informative HMC and GAMP-RIE suggests they offer comparable performance in this scenario. The parameter α likely controls some aspect of the MCMC algorithm's step size or adaptation, and the chart shows how the convergence rate changes as this parameter is adjusted. The error bars are crucial for understanding the reliability of each method's convergence, with smaller error bars indicating more consistent performance. The chart suggests that the choice of MCMC algorithm and the tuning of its parameters (like α) are critical for achieving efficient and accurate Bayesian inference.