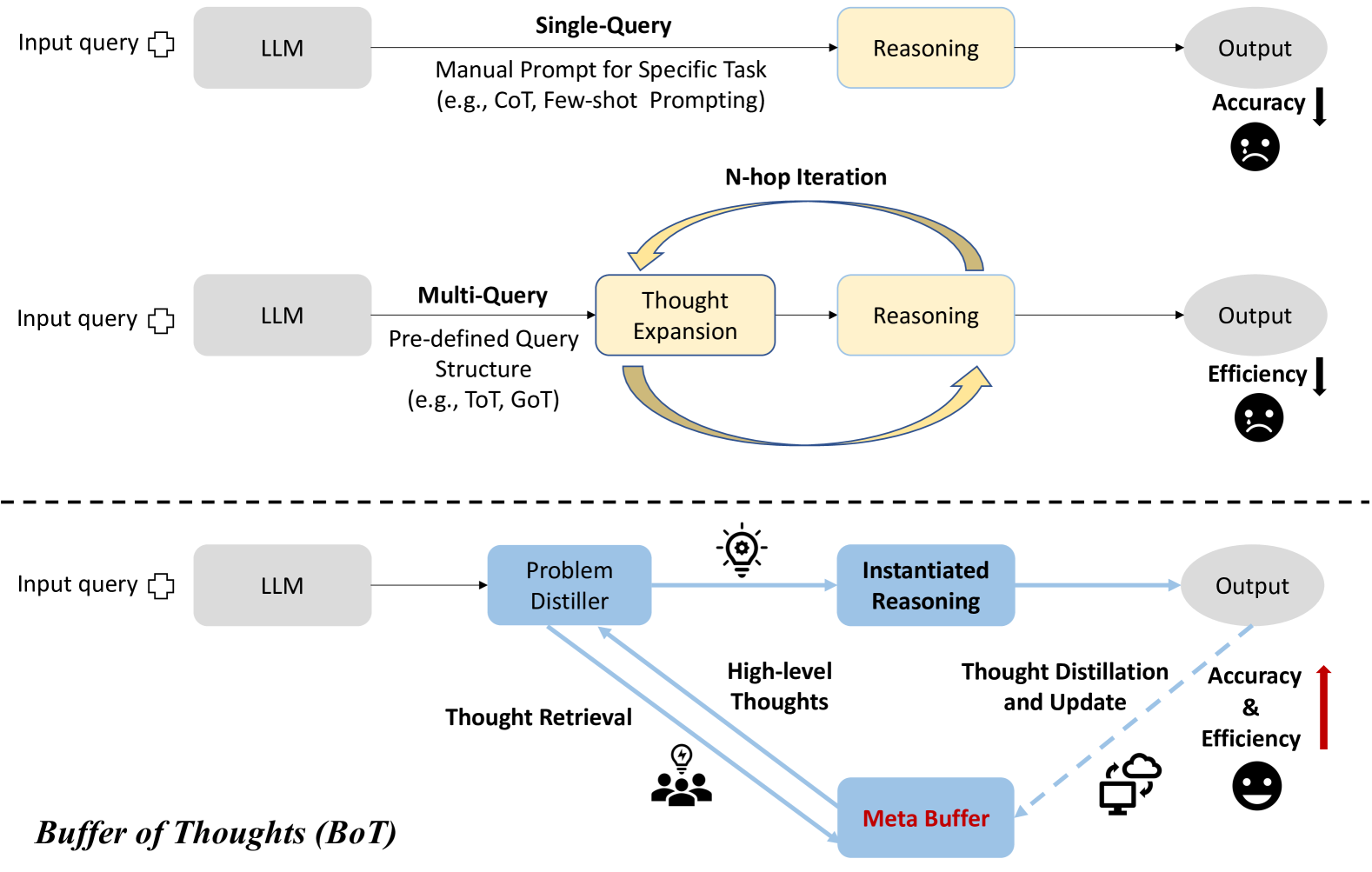
## [Diagram]: LLM Reasoning Approaches (Single-Query, Multi-Query, Buffer of Thoughts)
### Overview
The image is a comparative diagram of three Large Language Model (LLM) reasoning workflows: **Single-Query**, **Multi-Query**, and **Buffer of Thoughts (BoT)**. It visually contrasts their components, processes, and performance (accuracy/efficiency) using icons, arrows, and labels.
### Components/Sections (Top to Bottom)
The diagram is divided into three horizontal sections (separated by a dashed line), each representing a distinct LLM reasoning paradigm:
#### 1. Top Section: Single-Query Approach
- **Input**: "Input query" (with a plus icon) → fed to a gray rectangle labeled "LLM".
- **Process**: "Single-Query" with "Manual Prompt for Specific Task (e.g., CoT, Few-shot Prompting)" → leads to a yellow rectangle labeled "Reasoning".
- **Output**: Gray oval labeled "Output".
- **Metric**: "Accuracy" with a downward arrow and a sad face (indicating low accuracy).
#### 2. Middle Section: Multi-Query Approach
- **Input**: "Input query" (plus icon) → fed to a gray rectangle labeled "LLM".
- **Process**: "Multi-Query" with "Pre-defined Query Structure (e.g., ToT, GoT)" → leads to a yellow rectangle labeled "Thought Expansion", then to "Reasoning" (yellow rectangle). An "N-hop Iteration" loop (curved arrows) connects "Thought Expansion" and "Reasoning".
- **Output**: Gray oval labeled "Output".
- **Metric**: "Efficiency" with a downward arrow and a sad face (indicating low efficiency).
#### 3. Bottom Section: Buffer of Thoughts (BoT) Approach
- **Input**: "Input query" (plus icon) → fed to a gray rectangle labeled "LLM".
- **Process**:
- "Problem Distiller" (blue rectangle, lightbulb icon) → "Instantiated Reasoning" (blue rectangle) → "Output" (gray oval).
- "Meta Buffer" (blue rectangle, cloud/computer icon) stores "High-level Thoughts" (arrow from Problem Distiller to Meta Buffer) and enables "Thought Retrieval" (arrow from Meta Buffer to Problem Distiller, group icon).
- "Thought Distillation and Update" (dashed arrow from Output to Meta Buffer) refines stored thoughts.
- **Metric**: "Accuracy & Efficiency" with an upward arrow and a happy face (indicating improved accuracy and efficiency).
- **Label**: "Buffer of Thoughts (BoT)" at the bottom left.
### Detailed Analysis
- **Single-Query**: Relies on a single, manual prompt (e.g., Chain-of-Thought, few-shot) for reasoning. Simple but yields low accuracy (sad face, down arrow).
- **Multi-Query**: Uses a pre-defined query structure (e.g., Tree-of-Thought, Graph-of-Thought) with iterative "Thought Expansion" and "Reasoning" (N-hop loop). Improves reasoning but reduces efficiency (sad face, down arrow).
- **BoT**: Introduces a "Problem Distiller" to process queries, "Instantiated Reasoning" for output, and a "Meta Buffer" to store/reuse "High-level Thoughts". Thoughts are retrieved, distilled, and updated, balancing accuracy and efficiency (happy face, up arrow).
### Key Observations
- **Performance Contrast**: BoT is the only approach with a happy face (improved accuracy/efficiency), while Single-Query (low accuracy) and Multi-Query (low efficiency) have sad faces.
- **Component Complexity**: BoT adds unique components (Problem Distiller, Meta Buffer) and processes (Thought Retrieval, Distillation/Update) absent in the other two.
- **Trade-Off Resolution**: BoT addresses the accuracy-efficiency trade-off by reusing/refining thoughts via a meta-buffer, unlike the single/iterative approaches.
### Interpretation
The diagram illustrates the evolution of LLM reasoning:
- **Single-Query** is basic but ineffective (low accuracy).
- **Multi-Query** improves reasoning via iteration but sacrifices efficiency.
- **BoT** optimizes both by leveraging a "Meta Buffer" to store and refine high-level thoughts, mimicking human-like reasoning (reusing/refining processes). This suggests that a buffer of pre-processed thoughts (and distillation) can enhance LLM performance, addressing the limitations of simpler/iterative approaches. The BoT model likely aims to balance accuracy (quality) and efficiency (speed) by reusing and updating thought processes, making it a more robust solution for complex reasoning tasks.