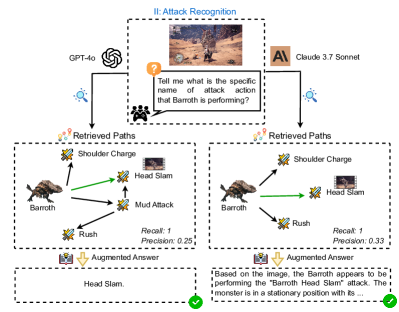
## Diagram: Attack Recognition Comparison - GPT-4o vs. Claude 3.7 Sonnet
### Overview
This diagram compares the performance of two Large Language Models (LLMs), GPT-4o and Claude 3.7 Sonnet, in recognizing attack actions performed by a creature named "Barroth". The diagram illustrates the input, processing, and output of each model, along with metrics for recall and precision. The diagram is divided into sections for each model, showing the retrieved paths of potential attacks and the final augmented answer.
### Components/Axes
The diagram consists of the following components:
* **Header:** "II: Attack Recognition" with an image of Barroth performing an attack.
* **Input:** A question posed to both models: "Tell me what is the specific name of attack action that Barroth is performing?" accompanied by an image of Barroth.
* **Model Representations:** Icons representing GPT-4o and Claude 3.7 Sonnet.
* **Retrieved Paths (GPT-4o):** A diagram showing Barroth at the center, with arrows pointing to potential attack actions: Shoulder Charge, Head Slam, Mud Attack, and Rush.
* **Retrieved Paths (Claude 3.7 Sonnet):** Similar to GPT-4o, showing Barroth with arrows to Shoulder Charge, Head Slam, and Rush.
* **Augmented Answer (GPT-4o):** "Head Slam."
* **Augmented Answer (Claude 3.7 Sonnet):** A text block stating: "Based on the image, the Barroth appears to be performing the 'Barroth Head Slam' attack. The monster is in a stationary position with its..."
* **Performance Metrics:** Recall and Precision values for each model.
* **Validation Indicators:** Green checkmarks indicating correct identification of the attack.
### Detailed Analysis / Content Details
**GPT-4o Section:**
* **Input:** The question "Tell me what is the specific name of attack action that Barroth is performing?" is presented with an image of Barroth.
* **Retrieved Paths:** Barroth is at the center.
* Green arrow from Barroth to Shoulder Charge.
* Green arrow from Barroth to Head Slam.
* Green arrow from Barroth to Mud Attack.
* Green arrow from Barroth to Rush.
* **Augmented Answer:** "Head Slam."
* **Performance Metrics:** Recall: 1, Precision: 0.25.
* **Validation:** A green checkmark is present.
**Claude 3.7 Sonnet Section:**
* **Input:** Same question and image as GPT-4o.
* **Retrieved Paths:** Barroth is at the center.
* Green arrow from Barroth to Shoulder Charge.
* Green arrow from Barroth to Head Slam.
* Green arrow from Barroth to Rush.
* **Augmented Answer:** "Based on the image, the Barroth appears to be performing the 'Barroth Head Slam' attack. The monster is in a stationary position with its..."
* **Performance Metrics:** Recall: 1, Precision: 0.33.
* **Validation:** A green checkmark is present.
### Key Observations
* Both models correctly identify "Head Slam" as the attack.
* Claude 3.7 Sonnet provides a more detailed explanation of its reasoning, including the monster's stationary position.
* Claude 3.7 Sonnet has a higher precision score (0.33) compared to GPT-4o (0.25), suggesting it is more selective in its attack predictions.
* Both models have a recall of 1, indicating they successfully identified the correct attack when it was present in the retrieved paths.
* GPT-4o retrieves more potential attack paths (four) than Claude 3.7 Sonnet (three).
### Interpretation
The diagram demonstrates a comparison of two LLMs' ability to recognize a specific attack action from an image. Both models achieve a correct identification (indicated by the green checkmarks), but differ in their approach and performance metrics. Claude 3.7 Sonnet exhibits a higher precision, suggesting it is less prone to false positives, while GPT-4o explores a wider range of potential attacks. The detailed explanation provided by Claude 3.7 Sonnet offers insight into its reasoning process, which could be valuable for understanding its decision-making. The difference in precision could be attributed to the models' underlying architectures, training data, or prompting strategies. The diagram highlights the potential of LLMs for visual recognition tasks, specifically in identifying actions within complex scenes. The recall of 1 for both models suggests that when the correct attack is considered, both models are capable of identifying it.