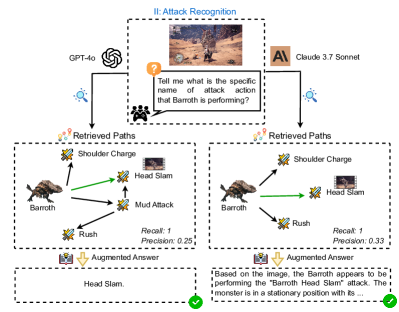
## Flowchart: Attack Recognition Process Comparison
### Overview
The diagram compares two AI models (GPT-4o and Claude 3.7 Sonnet) in their approach to recognizing attack actions performed by a "Barroth" creature in a game context. Each model processes a query ("Tell me what is the specific name of attack action that Barroth is performing?") and generates retrieved paths of possible attack actions, along with recall/precision metrics and augmented answers.
### Components/Axes
1. **Models**:
- **GPT-4o** (left side, labeled with a gear icon).
- **Claude 3.7 Sonnet** (right side, labeled with an "A" icon).
2. **Retrieved Paths**:
- **GPT-4o Paths**:
- Shoulder Charge → Head Slam
- Mud Attack
- Rush
- Metrics: Recall = 1, Precision = 0.25
- **Claude 3.7 Sonnet Paths**:
- Shoulder Charge → Head Slam
- Rush
- Metrics: Recall = 1, Precision = 0.33
3. **Augmented Answers**:
- **GPT-4o**: "Head Slam."
- **Claude 3.7 Sonnet**: "Based on the image, the Barroth appears to be performing the 'Barroth Head Slam' attack. The monster is in a stationary position with its..."
4. **Visual Elements**:
- Icons for attack actions (e.g., sword for Head Slam, shield for Shoulder Charge).
- Green arrows indicating flow between actions.
- Text boxes for queries, paths, and answers.
### Detailed Analysis
- **GPT-4o**:
- Lists three attack actions (Shoulder Charge, Mud Attack, Rush) with Head Slam as the final answer.
- High recall (1) but low precision (0.25), suggesting it identifies all possible actions but with many false positives.
- **Claude 3.7 Sonnet**:
- Lists two attack actions (Shoulder Charge, Rush) with Head Slam as the final answer.
- Higher precision (0.33) than GPT-4o, indicating more accurate identification despite fewer paths.
- **Augmented Answers**:
- GPT-4o provides a concise answer ("Head Slam").
- Claude 3.7 Sonnet adds contextual details about the Barroth’s stationary position.
### Key Observations
1. Both models achieve **perfect recall** (1), meaning they capture all possible attack actions.
2. **Precision disparity**: Claude 3.7 Sonnet (0.33) outperforms GPT-4o (0.25), suggesting better accuracy in narrowing down the correct action.
3. **Augmented answers**: Claude’s response includes richer contextual analysis compared to GPT-4o’s brevity.
### Interpretation
The diagram highlights trade-offs between recall and precision in AI-driven attack recognition. While both models identify all possible actions (high recall), Claude 3.7 Sonnet demonstrates superior precision, likely due to more refined contextual analysis. The augmented answers reflect this: Claude’s response incorporates environmental context (stationary position), whereas GPT-4o’s answer is purely categorical. This suggests Claude may be better suited for scenarios requiring nuanced interpretation, while GPT-4o prioritizes breadth over specificity.
**Note**: No non-English text or additional data tables are present. All values and labels are explicitly stated in the diagram.