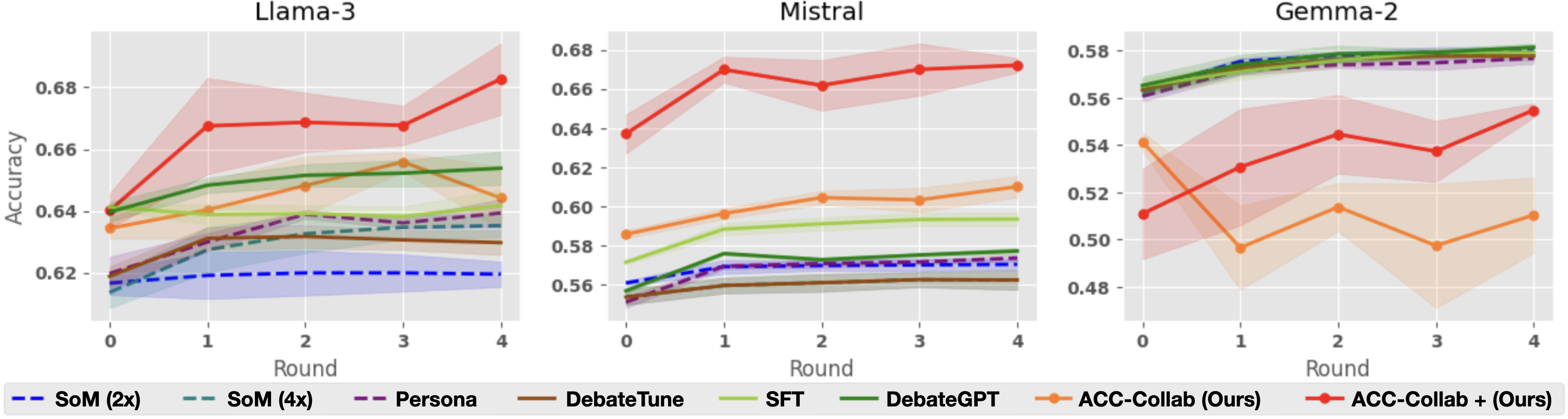
\n
## Line Chart: Accuracy vs. Round for Different Models and Training Methods
### Overview
This image presents three line charts, each displaying the accuracy of different language models (Llama-3, Mistral, and Gemma-2) across four rounds of evaluation. Each chart shows the performance of various training methods applied to the respective model. The accuracy is plotted on the y-axis, and the round number is on the x-axis. Shaded areas around each line represent confidence intervals.
### Components/Axes
* **X-axis:** Round (0, 1, 2, 3, 4)
* **Y-axis:** Accuracy (ranging approximately from 0.48 to 0.68)
* **Models (Charts):** Llama-3, Mistral, Gemma-2
* **Training Methods (Legend):**
* SoM (2x) - Dashed dark blue line
* SoM (4x) - Dashed light blue line
* Persona - Solid purple line
* DebateTune - Solid green line
* SFT - Solid orange line
* DebateGPT - Solid teal line
* ACC-Collab (Ours) - Solid red line
* ACC-Collab + (Ours) - Dashed red line
* **Legend Position:** Bottom-center of the image, spanning all three charts.
### Detailed Analysis or Content Details
**Llama-3 Chart (Left):**
* **ACC-Collab (Ours):** Starts at approximately 0.64, increases to around 0.67 at round 1, then fluctuates around 0.67-0.68 for rounds 2-4.
* **ACC-Collab + (Ours):** Starts at approximately 0.63, increases to around 0.66 at round 1, then fluctuates around 0.66-0.67 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.62, increases to around 0.64 at round 1, then remains relatively stable around 0.64-0.65 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.61, increases to around 0.63 at round 1, then remains relatively stable around 0.63-0.64 for rounds 2-4.
* **Persona:** Starts at approximately 0.63, increases to around 0.65 at round 1, then remains relatively stable around 0.65-0.66 for rounds 2-4.
* **DebateTune:** Starts at approximately 0.62, increases to around 0.65 at round 1, then remains relatively stable around 0.65-0.66 for rounds 2-4.
* **SFT:** Starts at approximately 0.62, increases to around 0.65 at round 1, then remains relatively stable around 0.65-0.66 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.62, increases to around 0.65 at round 1, then remains relatively stable around 0.65-0.66 for rounds 2-4.
**Mistral Chart (Center):**
* **ACC-Collab (Ours):** Starts at approximately 0.67, decreases to around 0.66 at round 1, then fluctuates around 0.66-0.67 for rounds 2-4.
* **ACC-Collab + (Ours):** Starts at approximately 0.65, increases to around 0.66 at round 1, then fluctuates around 0.66-0.67 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.56, increases to around 0.58 at round 1, then remains relatively stable around 0.58-0.59 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.56, increases to around 0.58 at round 1, then remains relatively stable around 0.58-0.59 for rounds 2-4.
* **Persona:** Starts at approximately 0.57, increases to around 0.59 at round 1, then remains relatively stable around 0.59-0.60 for rounds 2-4.
* **DebateTune:** Starts at approximately 0.58, increases to around 0.60 at round 1, then remains relatively stable around 0.60-0.61 for rounds 2-4.
* **SFT:** Starts at approximately 0.58, increases to around 0.60 at round 1, then remains relatively stable around 0.60-0.61 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.58, increases to around 0.60 at round 1, then remains relatively stable around 0.60-0.61 for rounds 2-4.
**Gemma-2 Chart (Right):**
* **ACC-Collab (Ours):** Starts at approximately 0.50, increases to around 0.54 at round 1, then fluctuates around 0.55-0.56 for rounds 2-4.
* **ACC-Collab + (Ours):** Starts at approximately 0.49, increases to around 0.56 at round 1, then remains relatively stable around 0.56-0.57 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.52, increases to around 0.55 at round 1, then remains relatively stable around 0.55-0.56 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.52, increases to around 0.55 at round 1, then remains relatively stable around 0.55-0.56 for rounds 2-4.
* **Persona:** Starts at approximately 0.53, increases to around 0.56 at round 1, then remains relatively stable around 0.56-0.57 for rounds 2-4.
* **DebateTune:** Starts at approximately 0.53, increases to around 0.56 at round 1, then remains relatively stable around 0.56-0.57 for rounds 2-4.
* **SFT:** Starts at approximately 0.53, increases to around 0.56 at round 1, then remains relatively stable around 0.56-0.57 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.53, increases to around 0.56 at round 1, then remains relatively stable around 0.56-0.57 for rounds 2-4.
### Key Observations
* **Llama-3** consistently exhibits the highest accuracy across all training methods and rounds.
* **Mistral** shows moderate accuracy, generally lower than Llama-3 but higher than Gemma-2.
* **Gemma-2** has the lowest overall accuracy.
* For all models, accuracy generally increases from round 0 to round 1, then plateaus or fluctuates slightly in subsequent rounds.
* The "ACC-Collab (Ours)" method generally performs well across all models, often achieving the highest accuracy.
* The "ACC-Collab + (Ours)" method shows similar performance to "ACC-Collab (Ours)".
### Interpretation
The charts demonstrate the effectiveness of different training methods on various language models. Llama-3 appears to be the most capable model, achieving significantly higher accuracy than Mistral and Gemma-2. The "ACC-Collab" training approach consistently yields strong results, suggesting its suitability for improving model performance. The initial accuracy gains observed from round 0 to round 1 indicate that the training process is effective in the early stages, but further rounds yield diminishing returns. The confidence intervals (shaded areas) suggest some variability in the results, but the overall trends are clear. The data suggests that model choice and training method are both crucial factors in achieving high accuracy in language models. The relatively stable performance after round 1 could indicate that the models are approaching their performance limits with the given training data and methods.