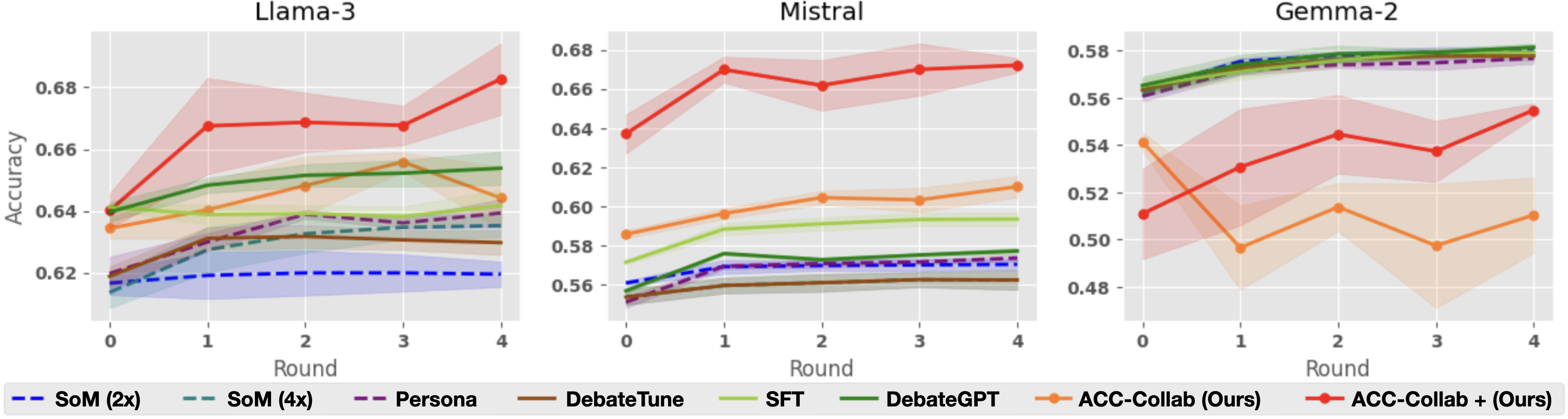
## Line Graphs: Model Performance Across Rounds
### Overview
The image contains three line graphs comparing the accuracy of different AI models across four rounds of evaluation. Each graph represents a different base model (Llama-3, Mistral, Gemma-2), with performance metrics tracked for multiple fine-tuning approaches. The graphs use colored lines with shaded confidence intervals to visualize performance trends.
### Components/Axes
- **X-axis**: Round (0 to 4, integer values)
- **Y-axis**: Accuracy (0.54 to 0.68, decimal values)
- **Legends**:
- **Llama-3**:
- Blue dashed: SoM (2x)
- Teal dashed: SoM (4x)
- Purple dashed: Persona
- Brown solid: DebateTune
- Green solid: SIFT
- Orange solid: DebateGPT
- Red solid: ACC-Collab (Ours)
- Red solid with gradient: ACC-Collab + (Ours)
- **Mistral**: Same legend as Llama-3
- **Gemma-2**: Same legend as Llama-3
- **Graph Titles**: Llama-3 (top-left), Mistral (top-center), Gemma-2 (top-right)
### Detailed Analysis
#### Llama-3
- **ACC-Collab (Ours)**: Starts at ~0.63 (Round 0), peaks at ~0.68 (Round 4)
- **ACC-Collab + (Ours)**: Starts at ~0.62 (Round 0), peaks at ~0.68 (Round 4)
- **Other Models**:
- DebateGPT (green) shows steady growth from ~0.64 to ~0.66
- SIFT (yellow) fluctuates between ~0.63-0.65
- SoM (2x/4x) and Persona (purple) remain below 0.64
#### Mistral
- **ACC-Collab (Ours)**: Starts at ~0.64 (Round 0), peaks at ~0.67 (Round 1), then stabilizes
- **ACC-Collab + (Ours)**: Starts at ~0.63 (Round 0), peaks at ~0.67 (Round 4)
- **Other Models**:
- DebateGPT (green) grows from ~0.56 to ~0.58
- SIFT (yellow) increases from ~0.57 to ~0.60
- SoM (2x/4x) and Persona (purple) remain below 0.60
#### Gemma-2
- **ACC-Collab (Ours)**: Starts at ~0.54 (Round 0), dips to ~0.52 (Round 1), peaks at ~0.56 (Round 4)
- **ACC-Collab + (Ours)**: Starts at ~0.56 (Round 0), dips to ~0.54 (Round 1), peaks at ~0.57 (Round 4)
- **Other Models**:
- DebateGPT (green) shows steady growth from ~0.56 to ~0.58
- SIFT (yellow) increases from ~0.57 to ~0.59
- SoM (2x/4x) and Persona (purple) remain below 0.56
### Key Observations
1. **ACC-Collab + (Ours)** consistently outperforms **ACC-Collab (Ours)** in later rounds across all base models
2. **Gemma-2** shows the most significant performance gap between the two ACC-Collab variants
3. **DebateGPT** and **SIFT** demonstrate gradual improvement across all base models
4. **SoM (4x)** and **Persona** show minimal growth compared to other methods
5. Confidence intervals (shaded areas) indicate higher variability in Mistral's performance
### Interpretation
The data suggests that combining ACC-Collab with additional optimization techniques ("Ours") enhances model performance, particularly in later evaluation rounds. This trend is most pronounced in Mistral and Gemma-2, where ACC-Collab + (Ours) achieves 2-3% higher accuracy than the base ACC-Collab approach. The gradual improvement of DebateGPT and SIFT across all models indicates their effectiveness as fine-tuning strategies, though they don't match the peak performance of ACC-Collab variants. The stability of SoM and Persona methods suggests they may be less sensitive to iterative refinement. The widening confidence intervals in Mistral's graph highlight potential instability in its evaluation process compared to the other models.