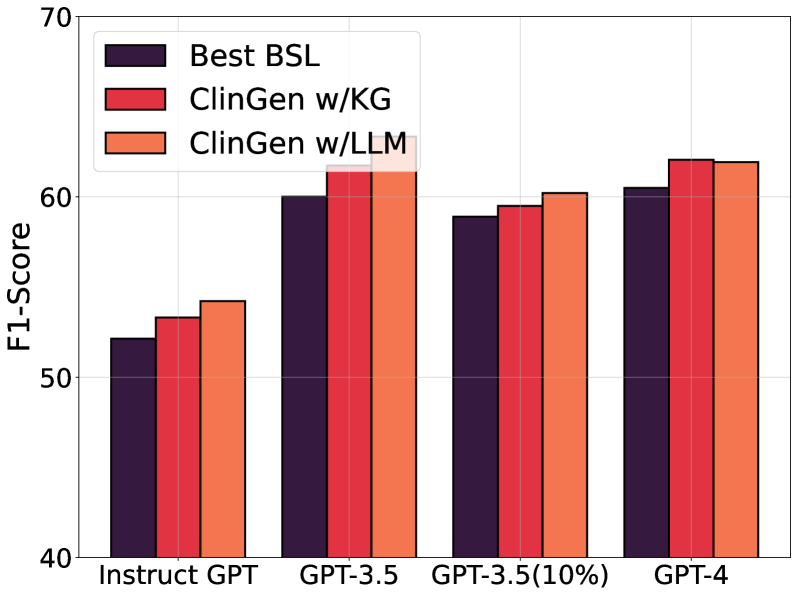
# Technical Document Extraction: Bar Chart Analysis
## Axis Labels and Markers
- **Y-Axis**:
- Title: `F1-Score`
- Range: `40` to `70` (in increments of 10)
- Units: Not explicitly stated (assumed unitless score)
- **X-Axis**:
- Categories:
1. `Instruct GPT`
2. `GPT-3.5`
3. `GPT-3.5(10%)`
4. `GPT-4`
## Legend
- **Labels and Colors**:
- `Best BSL`: Dark purple (`#4B0082`)
- `ClinGen w/KG`: Red (`#FF0000`)
- `ClinGen w/LLM`: Orange (`#FFA500`)
## Data Points and Trends
### By Model Category
1. **Instruct GPT**:
- `Best BSL`: ~52
- `ClinGen w/KG`: ~54
- `ClinGen w/LLM`: ~55
- **Trend**: ClinGen w/LLM > ClinGen w/KG > Best BSL
2. **GPT-3.5**:
- `Best BSL`: ~60
- `ClinGen w/KG`: ~62
- `ClinGen w/LLM`: ~63
- **Trend**: ClinGen w/LLM > ClinGen w/KG > Best BSL
3. **GPT-3.5(10%)**:
- `Best BSL`: ~59
- `ClinGen w/KG`: ~59.5
- `ClinGen w/LLM`: ~60.5
- **Trend**: ClinGen w/LLM > ClinGen w/KG > Best BSL
4. **GPT-4**:
- `Best BSL`: ~61
- `ClinGen w/KG`: ~63
- `ClinGen w/LLM`: ~63
- **Trend**: ClinGen w/KG ≈ ClinGen w/LLM > Best BSL
### Overall Observations
- **Performance Hierarchy**:
- `ClinGen w/LLM` consistently outperforms `ClinGen w/KG` and `Best BSL` across all models.
- `GPT-4` achieves the highest F1-scores for all methods, followed by `GPT-3.5`, `GPT-3.5(10%)`, and `Instruct GPT`.
- **Notable Gaps**:
- `Best BSL` lags significantly behind ClinGen methods in all categories (e.g., ~11-point gap in `GPT-4`).
- `GPT-3.5(10%)` shows minimal improvement over `Instruct GPT` for `Best BSL` (~7-point increase).
## Structural Notes
- **Bar Grouping**: Each x-axis category contains three clustered bars (one per legend label).
- **Color Consistency**: Legend colors match bar colors without ambiguity.
- **No Missing Data**: All categories and methods are represented.
## Transcribed Text Embedded in Diagram
- Legend text: `"Best BSL"`, `"ClinGen w/KG"`, `"ClinGen w/LLM"`.
- Axis titles: `"F1-Score"` (y-axis), `"Instruct GPT"`, `"GPT-3.5"`, `"GPT-3.5(10%)"`, `"GPT-4"` (x-axis).
## Conclusion
The chart demonstrates that `ClinGen w/LLM` achieves the highest F1-scores across all GPT variants, with `GPT-4` yielding the strongest performance overall. `Best BSL` underperforms relative to ClinGen methods in every case.