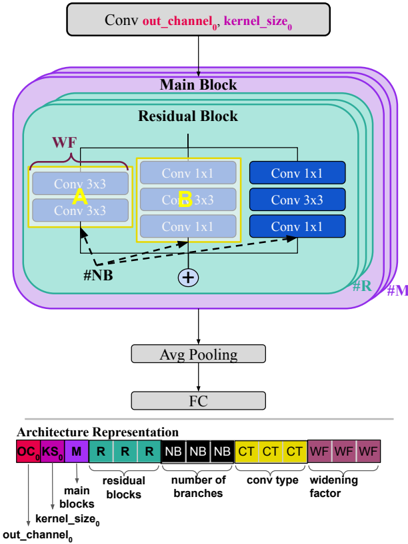
## Diagram: Residual Neural Network Architecture
### Overview
The diagram illustrates a residual neural network (ResNet) architecture with a focus on residual blocks, convolutional layers, and pooling operations. It includes a hierarchical structure with widening factors and branching mechanisms, visualized through color-coded components and labeled connections.
### Components/Axes
1. **Main Diagram Elements**:
- **Conv**: Convolutional layer with parameters `out_channel_0` and `kernel_size_0`.
- **Main Block**: Contains multiple residual blocks.
- **Residual Block**: Composed of:
- **WF (Widening Factor)**: Indicated by purple blocks.
- **Conv 3x3**: Two parallel 3x3 convolutional layers (labeled "A" and "B").
- **Conv 1x1**: Three sequential 1x1 convolutional layers (labeled "A", "B", and "C").
- **Shortcut Connection**: Dashed line bypassing the residual block.
- **Avg Pooling**: Average pooling layer.
- **FC**: Fully connected (dense) layer.
2. **Architecture Representation**:
- **Color-Coded Legend**:
- **OC (Out Channel)**: Red (`OC_0`).
- **KS (Kernel Size)**: Purple (`KS_0`).
- **M (Main Blocks)**: Purple (`M`).
- **R (Residual Blocks)**: Teal (`R`).
- **NB (Number of Branches)**: Black (`NB`).
- **CT (Conv Type)**: Yellow (`CT`).
- **WF (Widening Factor)**: Magenta (`WF`).
### Detailed Analysis
- **Residual Block Structure**:
- The residual block (teal) includes two parallel paths:
1. **Path A**: Two `Conv 3x3` layers (yellow blocks).
2. **Path B**: Three `Conv 1x1` layers (blue blocks).
- A shortcut connection (dashed line) skips the residual block, enabling direct addition of inputs to outputs (residual learning).
- **Widening Factor (WF)**:
- Purple blocks indicate multiplicative scaling of channel dimensions across layers.
- **Branching Mechanism**:
- Three branches (`NB = 3`) are represented by black blocks, suggesting parallel processing paths.
- **Conv Type (CT)**:
- Yellow blocks denote the type of convolution (e.g., standard vs. dilated).
### Key Observations
1. **Hierarchical Design**:
- The network progresses from input (`Conv`) through stacked residual blocks to a final fully connected layer (`FC`).
2. **Residual Learning**:
- Shortcut connections (dashed lines) allow gradients to flow directly, mitigating vanishing gradient issues in deep networks.
3. **Modularity**:
- The architecture representation summarizes the model's configuration using color-coded blocks, simplifying parameter tracking.
### Interpretation
This diagram represents a ResNet variant with residual blocks, widening factors, and branching mechanisms. The use of shortcut connections and residual learning enables training of deeper networks by preserving gradient flow. The architecture representation provides a compact summary of hyperparameters (e.g., `out_channel_0`, `kernel_size_0`, `WF`), which are critical for model configuration. The absence of numerical values suggests this is a schematic diagram rather than a trained model visualization. The widening factor (`WF`) likely scales channel dimensions to balance depth and computational cost, while the branching mechanism (`NB = 3`) introduces parallelism for feature extraction.