\n
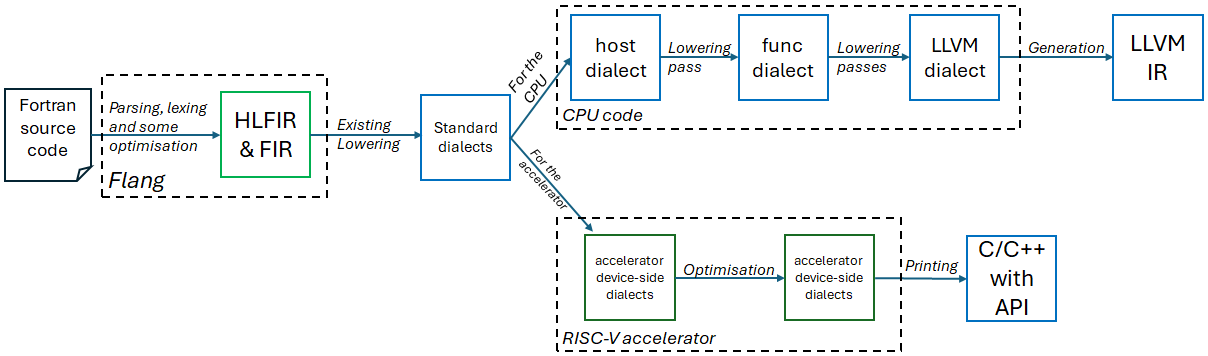
## Diagram: Fortran Compilation Pipeline
### Overview
This diagram illustrates the compilation pipeline for Fortran source code, specifically focusing on how it's processed for both CPU and accelerator (RISC-V) targets. The process begins with Fortran source code and culminates in either LLVM Intermediate Representation (IR) for the CPU or C/C++ code with an API for the accelerator. The diagram uses boxes to represent stages and arrows to indicate the flow of data/transformation.
### Components/Axes
The diagram is structured into two main branches: one for CPU compilation and one for accelerator compilation. Key components include:
* **Fortran source code:** The initial input.
* **Flang:** The Fortran front-end compiler.
* **HLFIR & FIR:** Intermediate Representation.
* **Existing Lowering:** A transformation step.
* **Standard dialects:** A collection of compilation dialects.
* **For the CPU:** Indicates the CPU compilation path.
* **host dialect:** A compilation dialect.
* **func dialect:** A compilation dialect.
* **LLVM dialect:** A compilation dialect.
* **Generation:** A transformation step.
* **LLVM IR:** The output for CPU compilation.
* **For the accelerator:** Indicates the accelerator compilation path.
* **accelerator device-side dialects:** Compilation dialects for the accelerator.
* **Optimisation:** A transformation step.
* **Printing:** A transformation step.
* **C/C++ with API:** The output for accelerator compilation.
* **RISC-V accelerator:** The target accelerator.
### Detailed Analysis or Content Details
The compilation process can be broken down as follows:
1. **Fortran Source Code** is processed by **Flang**, which performs parsing, lexing, and some optimization.
2. **Flang** outputs **HLFIR & FIR**.
3. **HLFIR & FIR** undergoes **Existing Lowering**.
4. The result is then processed using **Standard dialects**.
5. The process splits into two paths:
* **CPU Path:**
* **Standard dialects** are transformed using the **host dialect**, followed by a **Lowering pass**.
* The output is then processed by the **func dialect**, followed by further **Lowering passes**.
* Finally, the **LLVM dialect** is used for **Generation**, resulting in **LLVM IR**.
* **Accelerator Path:**
* **Standard dialects** are transformed using **accelerator device-side dialects**.
* This is followed by **Optimisation**.
* Further processing with **accelerator device-side dialects** leads to **Printing**, which generates **C/C++ with API**.
The dashed boxes visually group related stages. The CPU path is positioned above the accelerator path.
### Key Observations
The diagram highlights a common compiler infrastructure where a single source language (Fortran) can be targeted to different hardware platforms (CPU and RISC-V accelerator) through a series of transformations and intermediate representations. The use of dialects suggests a modular and extensible compilation framework. The accelerator path generates C/C++ code, implying that the accelerator relies on a C/C++ runtime or API for interaction.
### Interpretation
This diagram demonstrates a modern compiler design that leverages intermediate representations (HLFIR, FIR, LLVM IR) and a dialect-based approach to facilitate code generation for diverse hardware targets. The separation of CPU and accelerator compilation paths indicates a heterogeneous computing environment where the Fortran code is optimized for both general-purpose processors and specialized accelerators. The generation of C/C++ code for the accelerator suggests a strategy of offloading computation to the accelerator via a well-defined API. The diagram suggests a sophisticated compilation process that goes beyond simple translation and involves multiple optimization and lowering steps to achieve high performance on both CPU and accelerator platforms. The use of "dialects" implies a structured approach to compiler transformations, allowing for modularity and easier maintenance.