TECHNICAL ASSET FINGERPRINT
585b9a05ec805b91f4b147cd
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
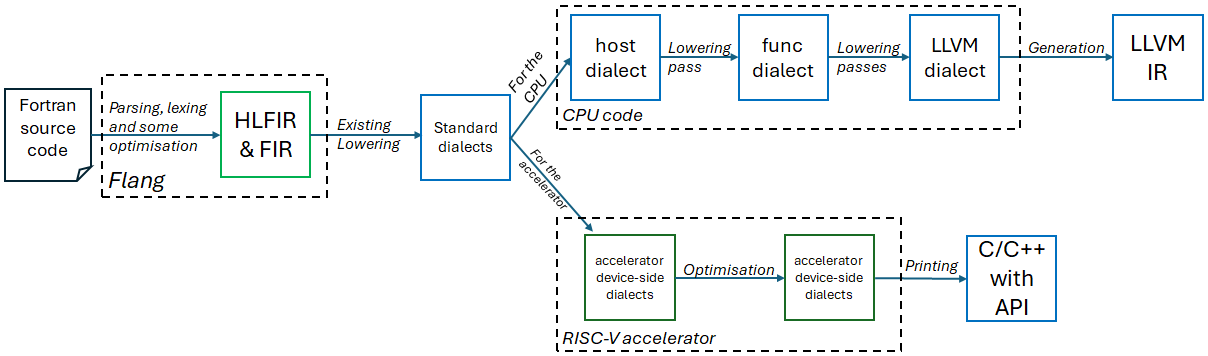
## Compilation Flowchart: Fortran to CPU and Accelerator Targets
### Overview
This image is a technical flowchart illustrating the compilation pipeline for Fortran source code, targeting both CPU and accelerator (specifically RISC-V) architectures. The diagram shows a branching process where initial parsing and optimization lead to two distinct code generation paths: one for traditional CPU execution and another for accelerator devices. The flowchart uses a combination of solid and dashed boxes, directional arrows with labels, and color-coding to denote different stages and components.
### Components/Axes
The diagram is structured as a directed graph flowing from left to right. Key components are enclosed in boxes, with dashed boxes grouping related stages.
**Primary Components (Boxes):**
1. **Fortran source code** (Leftmost, solid black outline)
2. **Flang** (Dashed black outline, containing the next stage)
3. **HLFIR & FIR** (Solid green outline, inside the Flang box)
4. **Standard dialects** (Solid blue outline)
5. **CPU code** (Dashed black outline, top branch)
* **host dialect** (Solid blue outline)
* **func dialect** (Solid blue outline)
* **LLVM dialect** (Solid blue outline)
6. **LLVM IR** (Solid blue outline, rightmost of top branch)
7. **RISC-V accelerator** (Dashed black outline, bottom branch)
* **accelerator device-side dialects** (Solid green outline, first box)
* **accelerator device-side dialects** (Solid green outline, second box)
8. **C/C++ with API** (Solid blue outline, rightmost of bottom branch)
**Flow Labels (Text on Arrows):**
* `Parsing, lexing and some optimisation` (Arrow from Fortran source to HLFIR & FIR)
* `Existing Lowering` (Arrow from HLFIR & FIR to Standard dialects)
* `For the CPU` (Arrow branching upward from Standard dialects)
* `For the accelerator` (Arrow branching downward from Standard dialects)
* `Lowering pass` (Arrow from host dialect to func dialect)
* `Lowering passes` (Arrow from func dialect to LLVM dialect)
* `Generation` (Arrow from LLVM dialect to LLVM IR)
* `Optimisation` (Arrow between the two "accelerator device-side dialects" boxes)
* `Printing` (Arrow from the second accelerator dialects box to C/C++ with API)
### Detailed Analysis
The pipeline begins with **Fortran source code** as input. This enters the **Flang** compiler frontend, where it undergoes **Parsing, lexing and some optimisation** to produce **HLFIR & FIR** (High-Level Fortran IR and Fortran IR).
From HLFIR & FIR, an **Existing Lowering** step produces **Standard dialects**. At this point, the pipeline bifurcates based on the target hardware:
**1. CPU Code Generation Path (Top Branch):**
* The flow is labeled `For the CPU`.
* The **Standard dialects** are lowered to a **host dialect**.
* A **Lowering pass** transforms the **host dialect** into a **func dialect**.
* Multiple **Lowering passes** then convert the **func dialect** into an **LLVM dialect**.
* Finally, a **Generation** step produces the final **LLVM IR** (Intermediate Representation), which is the standard output for CPU-targeting compilers.
**2. RISC-V Accelerator Code Generation Path (Bottom Branch):**
* The flow is labeled `For the accelerator`.
* The **Standard dialects** are lowered to **accelerator device-side dialects** (first green box).
* An **Optimisation** step occurs, resulting in a second instance of **accelerator device-side dialects** (second green box). This suggests an iterative or multi-stage optimization process within the accelerator-specific IR.
* A **Printing** step then converts these optimized dialects into **C/C++ with API**, which is likely the source code representation used to program the accelerator, possibly with a vendor-specific API.
### Key Observations
* **Parallel Compilation Strategy:** The diagram explicitly shows a single frontend (Flang) feeding two distinct backend paths, enabling a single Fortran codebase to be compiled for heterogeneous systems (CPU + accelerator).
* **Dialect-Centric Design:** The use of "dialects" (host, func, LLVM, accelerator device-side) indicates a modular compiler architecture, likely based on MLIR (Multi-Level IR), where different representations are tailored for specific optimizations and hardware targets.
* **Asymmetric Final Outputs:** The CPU path culminates in a low-level IR (LLVM IR), while the accelerator path culminates in high-level source code (C/C++ with API). This suggests the accelerator compilation might be a source-to-source transformation, relying on a separate downstream compiler for final device code generation.
* **Color Coding:** Boxes with a green outline (HLFIR & FIR, accelerator device-side dialects) appear to represent Fortran-specific or accelerator-specific intermediate representations. Blue-outlined boxes represent more generic or target-specific IRs (Standard, host, func, LLVM, final outputs).
### Interpretation
This flowchart depicts a sophisticated, modern compiler infrastructure designed for performance portability in high-performance computing (HPC). The core innovation is the ability to take standard Fortran code and automatically generate both the CPU portion of an application and the offload kernels for an accelerator (here, a RISC-V based one).
The "Standard dialects" stage acts as a crucial pivot point. By lowering the initial Fortran IR to a common set of dialects, the compiler can then apply target-specific lowering and optimization strategies. The CPU path follows a well-established route towards LLVM IR, leveraging the mature LLVM ecosystem for code generation and optimization for traditional architectures.
The accelerator path is particularly interesting. Instead of generating binary code or LLVM IR directly, it "prints" C/C++ code with an API. This implies a strategy where the Fortran compiler handles the high-level semantics, data mapping, and kernel identification, while delegating the final, hardware-specific code generation and optimization to a dedicated C/C++ compiler for the accelerator. This could be due to the accelerator having a unique instruction set or programming model not directly supported by LLVM, or it could be a design choice to reuse existing accelerator programming frameworks (like CUDA or OpenCL, but for RISC-V).
In essence, the diagram illustrates a bridge between the legacy world of Fortran and modern heterogeneous computing, using a multi-level IR approach to manage complexity and target diversity.
DECODING INTELLIGENCE...