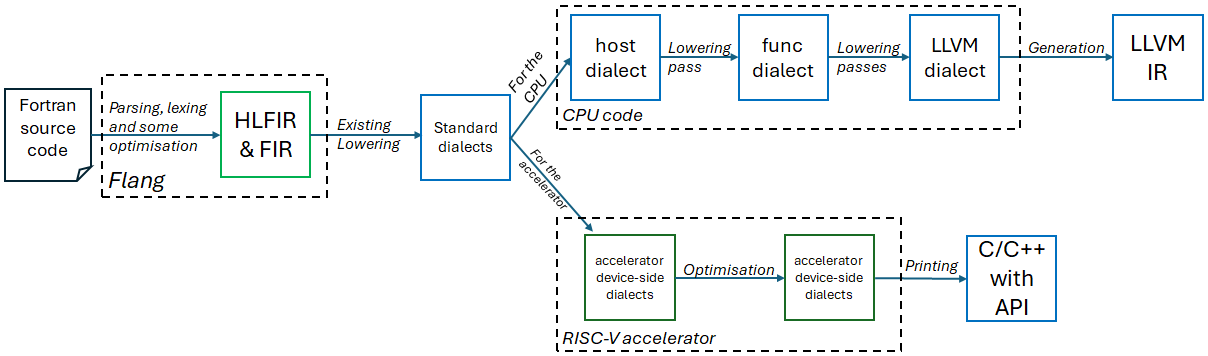
## Flowchart: Compilation and Optimization Pipeline for Fortran to LLVM IR
### Overview
The flowchart illustrates a multi-stage compilation and optimization pipeline for Fortran source code targeting LLVM IR, with specialized paths for CPU and RISC-V accelerator code generation. Key components include dialect lowering, optimization stages, and device-specific code generation.
### Components/Axes
- **Input**: Fortran source code (leftmost box)
- **Stages**:
1. **HLFIR & FIR**: Parsing, lexing, and optimization (green box)
2. **Standard dialects**: Splits into:
- **CPU code path**: Host dialect → func dialect → LLVM dialect → LLVM IR
- **Accelerator code path**: Accelerator device-side dialects → RISC-V accelerator optimization → C/C++ with API
- **Output**: LLVM IR (rightmost box)
- **Arrows**: Indicate flow direction with labels like "Lowering pass", "Optimisation", "Printing"
### Detailed Analysis
- **HLFIR & FIR Stage**:
- Processes Fortran code with parsing, lexing, and optimization.
- Outputs to "Standard dialects" for further lowering.
- **CPU Code Path**:
- Host dialect → func dialect → LLVM dialect → LLVM IR.
- Involves sequential lowering passes.
- **Accelerator Code Path**:
- Standard dialects → accelerator device-side dialects (optimized for RISC-V).
- Final output: C/C++ code with API for accelerator integration.
- **LLVM IR Generation**:
- Final output of the CPU path, used for further compilation or execution.
### Key Observations
- **Divergent Paths**: The pipeline splits at "Standard dialects" into CPU and accelerator-specific code generation.
- **Optimization Focus**: Both paths include optimization stages (e.g., "Optimisation" in RISC-V accelerator).
- **Device-Specific Dialects**: Accelerator code uses specialized dialects for RISC-V hardware.
### Interpretation
This flowchart represents a compiler architecture for Fortran-to-LLVM IR translation, emphasizing hardware-aware optimizations. The separation of CPU and accelerator code paths suggests a design for heterogeneous computing, where RISC-V accelerators require tailored dialects and optimizations. The use of dialects (e.g., host, func, LLVM) indicates intermediate representations tailored to specific hardware or abstraction levels. The final C/C++ API for the accelerator implies integration with existing toolchains or runtime systems. The pipeline’s structure highlights the complexity of modern compilers in balancing performance across diverse hardware targets.