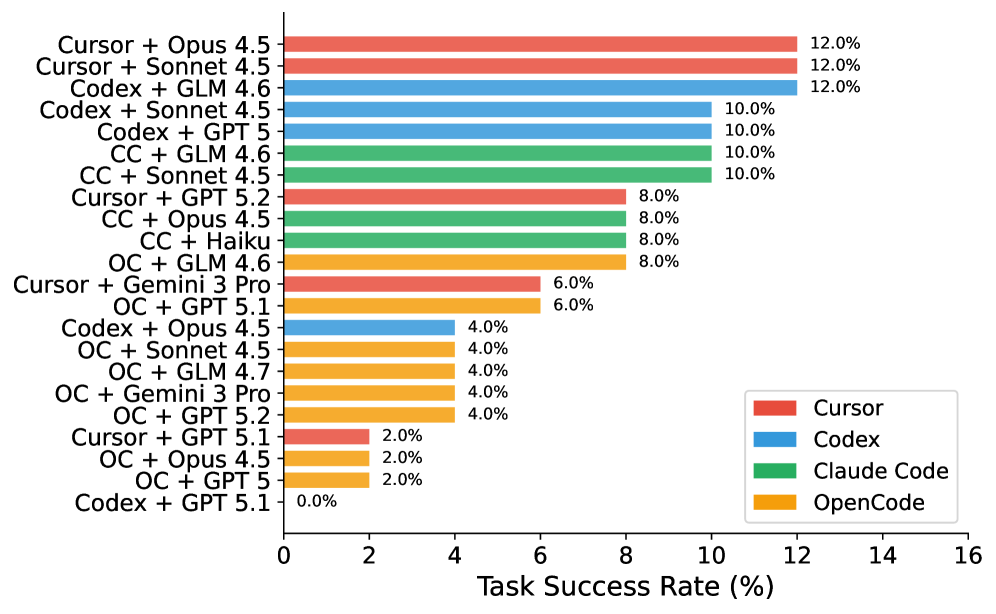
## Horizontal Bar Chart: Task Success Rates of Code Generation Models
### Overview
The chart compares task success rates (%) of various code generation models, categorized by base model (Cursor, Codex, Claude Code, OpenCode) and fine-tuning method (e.g., Opus 4.5, Sonnet 4.5, GPT 5). Success rates range from 0% to 16%, with the highest performers clustered near 12%.
### Components/Axes
- **X-axis**: Task Success Rate (%) (0–16 scale)
- **Y-axis**: Model combinations (e.g., "Cursor + Opus 4.5", "Codex + GPT 5")
- **Legend**:
- Red = Cursor
- Blue = Codex
- Green = Claude Code
- Yellow = OpenCode
- **Text Annotations**: Percentages (e.g., "12.0%") at the end of each bar
### Detailed Analysis
1. **Highest Performers (12.0%)**:
- Cursor + Opus 4.5 (red)
- Cursor + Sonnet 4.5 (red)
- Codex + GLM 4.6 (blue)
2. **Mid-Tier (10.0%)**:
- Codex + Sonnet 4.5 (blue)
- Codex + GPT 5 (blue)
- Claude Code + GLM 4.6 (green)
- Claude Code + Sonnet 4.5 (green)
- Claude Code + Opus 4.5 (green)
3. **Lower Tier (8.0%)**:
- Cursor + GPT 5.2 (red)
- Claude Code + Opus 4.5 (green)
- Claude Code + Haiku (green)
- OpenCode + GLM 4.6 (yellow)
4. **Low Performers (6.0–4.0%)**:
- Cursor + Gemini 3 Pro (red): 6.0%
- OpenCode + GPT 5.1 (yellow): 6.0%
- OpenCode + Opus 4.5 (yellow): 4.0%
- OpenCode + Sonnet 4.5 (yellow): 4.0%
- OpenCode + Gemini 3 Pro (yellow): 4.0%
- OpenCode + GPT 5.2 (yellow): 4.0%
5. **Outlier**:
- Codex + GPT 5.1 (blue): 0.0%
### Key Observations
- **Dominance of Cursor Models**: Cursor combinations with Opus 4.5 and Sonnet 4.5 achieve the highest success rates (12.0%).
- **Codex Variability**: Codex models perform well with GLM 4.6 (12.0%) but fail entirely with GPT 5.1 (0.0%).
- **OpenCode Underperformance**: All OpenCode combinations score ≤6.0%, with GPT 5.1 being the worst (0.0%).
- **Claude Code Consistency**: Claude Code models maintain 8–10% success rates across multiple fine-tuning methods.
### Interpretation
The data suggests that **Cursor models fine-tuned with Opus 4.5 and Sonnet 4.5** are the most effective for code generation tasks, outperforming other base models. **Codex models show inconsistency**, excelling with GLM 4.6 but failing catastrophically with GPT 5.1. **OpenCode models underperform across the board**, indicating potential limitations in their architecture or training data. The **0.0% success rate for Codex + GPT 5.1** warrants investigation—it may reflect incompatibility between the Codex base model and GPT 5.1 fine-tuning, or data quality issues. The clustering of success rates around 10–12% implies a ceiling effect for current state-of-the-art models, while the OpenCode results highlight opportunities for improvement in open-source code generation frameworks.