\n
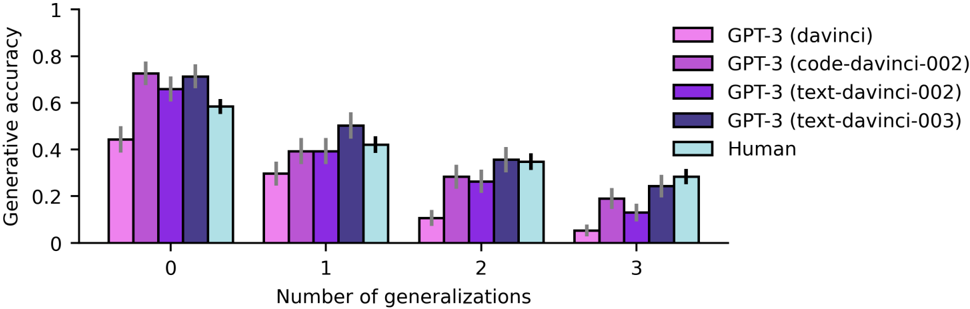
## Bar Chart: Generative Accuracy vs. Number of Generalizations
### Overview
This bar chart compares the generative accuracy of several GPT-3 models (davinci, code-davinci-002, text-davinci-002, text-davinci-003) and humans across different levels of generalization (0, 1, 2, and 3). Each bar represents the average generative accuracy, with error bars indicating the variability around that average.
### Components/Axes
* **X-axis:** "Number of generalizations" with markers at 0, 1, 2, and 3.
* **Y-axis:** "Generative accuracy" ranging from approximately 0 to 1.
* **Legend:** Located in the top-right corner, identifying the different models/groups:
* GPT-3 (davinci) - Magenta
* GPT-3 (code-davinci-002) - Dark Gray
* GPT-3 (text-davinci-002) - Purple
* GPT-3 (text-davinci-003) - Black
* Human - Light Blue
### Detailed Analysis
The chart consists of grouped bar plots for each level of generalization. Error bars are present for each bar, indicating the standard deviation or confidence interval.
* **Generalization 0:**
* GPT-3 (davinci): Approximately 0.74, with error bars ranging from 0.68 to 0.80.
* GPT-3 (code-davinci-002): Approximately 0.44, with error bars ranging from 0.38 to 0.50.
* GPT-3 (text-davinci-002): Approximately 0.66, with error bars ranging from 0.60 to 0.72.
* GPT-3 (text-davinci-003): Approximately 0.63, with error bars ranging from 0.57 to 0.69.
* Human: Approximately 0.70, with error bars ranging from 0.64 to 0.76.
* **Generalization 1:**
* GPT-3 (davinci): Approximately 0.32, with error bars ranging from 0.26 to 0.38.
* GPT-3 (code-davinci-002): Approximately 0.45, with error bars ranging from 0.40 to 0.50.
* GPT-3 (text-davinci-002): Approximately 0.44, with error bars ranging from 0.38 to 0.50.
* GPT-3 (text-davinci-003): Approximately 0.42, with error bars ranging from 0.36 to 0.48.
* Human: Approximately 0.44, with error bars ranging from 0.38 to 0.50.
* **Generalization 2:**
* GPT-3 (davinci): Approximately 0.25, with error bars ranging from 0.19 to 0.31.
* GPT-3 (code-davinci-002): Approximately 0.34, with error bars ranging from 0.28 to 0.40.
* GPT-3 (text-davinci-002): Approximately 0.28, with error bars ranging from 0.22 to 0.34.
* GPT-3 (text-davinci-003): Approximately 0.32, with error bars ranging from 0.26 to 0.38.
* Human: Approximately 0.32, with error bars ranging from 0.26 to 0.38.
* **Generalization 3:**
* GPT-3 (davinci): Approximately 0.08, with error bars ranging from 0.04 to 0.12.
* GPT-3 (code-davinci-002): Approximately 0.24, with error bars ranging from 0.18 to 0.30.
* GPT-3 (text-davinci-002): Approximately 0.21, with error bars ranging from 0.15 to 0.27.
* GPT-3 (text-davinci-003): Approximately 0.26, with error bars ranging from 0.20 to 0.32.
* Human: Approximately 0.26, with error bars ranging from 0.20 to 0.32.
### Key Observations
* Generative accuracy generally decreases as the number of generalizations increases for all models and humans.
* GPT-3 (davinci) exhibits the highest accuracy at generalization level 0, but its performance drops significantly with increasing generalization.
* GPT-3 (code-davinci-002) shows relatively stable performance across all generalization levels, though it starts with lower accuracy than GPT-3 (davinci).
* Human performance is comparable to the GPT-3 models at generalization levels 1, 2, and 3.
### Interpretation
The data suggests that the ability of these models to maintain accuracy diminishes as the complexity of the task (measured by the number of generalizations) increases. GPT-3 (davinci), while strong at simple tasks (0 generalizations), struggles with more abstract or complex scenarios. The more specialized model, GPT-3 (code-davinci-002), demonstrates more consistent performance, indicating it may be better suited for tasks requiring generalization. The human performance provides a baseline for comparison, showing that humans can perform comparably to the models at higher generalization levels. The error bars indicate that there is variability in the performance of each model, and the differences between models may not always be statistically significant. The steep decline in accuracy for GPT-3 (davinci) with increasing generalization suggests a limitation in its ability to transfer knowledge or reason abstractly. This could be due to its training data or the architecture of the model.