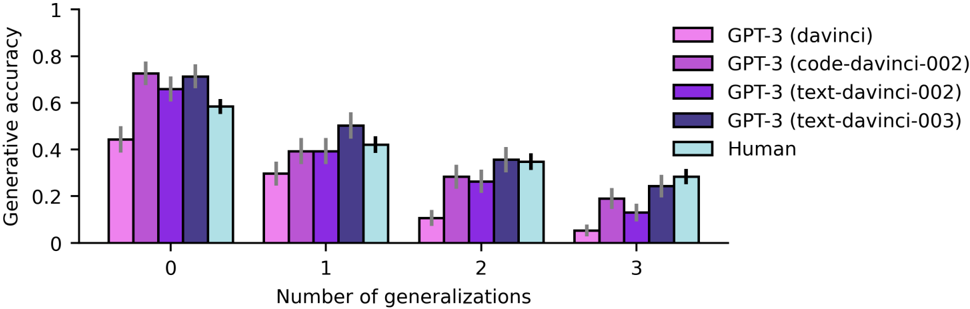
## Bar Chart: Generative Accuracy by Number of Generalizations
### Overview
The chart compares the generative accuracy of different GPT-3 models (davinci, code-davinci-002, text-davinci-002, text-davinci-003) and human performance across four categories of generalizations (0, 1, 2, 3). The y-axis represents generative accuracy (0–1), while the x-axis shows the number of generalizations. Error bars indicate variability in measurements.
### Components/Axes
- **X-axis**: "Number of generalizations" with categories 0, 1, 2, 3.
- **Y-axis**: "Generative accuracy" scaled from 0 to 1.
- **Legend**:
- Pink: GPT-3 (davinci)
- Purple: GPT-3 (code-davinci-002)
- Dark purple: GPT-3 (text-davinci-002)
- Dark blue: GPT-3 (text-davinci-003)
- Light blue: Human
- **Error bars**: Vertical lines on top of bars showing ±0.03–0.05 uncertainty.
### Detailed Analysis
- **Number of generalizations = 0**:
- Human: ~0.6 (±0.05)
- GPT-3 (davinci): ~0.45 (±0.03)
- GPT-3 (code-davinci-002): ~0.7 (±0.04)
- GPT-3 (text-davinci-002): ~0.65 (±0.04)
- GPT-3 (text-davinci-003): ~0.72 (±0.05)
- **Number of generalizations = 1**:
- Human: ~0.42 (±0.04)
- GPT-3 (davinci): ~0.3 (±0.03)
- GPT-3 (code-davinci-002): ~0.4 (±0.04)
- GPT-3 (text-davinci-002): ~0.38 (±0.04)
- GPT-3 (text-davinci-003): ~0.5 (±0.05)
- **Number of generalizations = 2**:
- Human: ~0.35 (±0.04)
- GPT-3 (davinci): ~0.12 (±0.03)
- GPT-3 (code-davinci-002): ~0.3 (±0.04)
- GPT-3 (text-davinci-002): ~0.28 (±0.04)
- GPT-3 (text-davinci-003): ~0.38 (±0.05)
- **Number of generalizations = 3**:
- Human: ~0.28 (±0.04)
- GPT-3 (davinci): ~0.05 (±0.03)
- GPT-3 (code-davinci-002): ~0.2 (±0.04)
- GPT-3 (text-davinci-002): ~0.15 (±0.04)
- GPT-3 (text-davinci-003): ~0.25 (±0.05)
### Key Observations
1. **Human performance** consistently exceeds all GPT-3 models across all generalization levels.
2. **GPT-3 (text-davinci-003)** outperforms other models at 0 and 1 generalizations but declines sharply at 2–3 generalizations.
3. **GPT-3 (davinci)** shows the steepest drop in accuracy as generalizations increase.
4. **Error bars** are largest for human data (0.05) and smallest for GPT-3 (davinci) (0.03), suggesting higher variability in human performance.
### Interpretation
The data demonstrates that **human generative accuracy degrades gracefully** with increasing generalizations, maintaining a ~0.28–0.6 range. In contrast, **GPT-3 models exhibit significant performance drops** beyond 1 generalization, with davinci models performing worst. The text-davinci-003 variant shows the most robust performance at low generalizations but fails to generalize effectively. Error bars indicate that **human variability is higher** than model variability, possibly due to subjective interpretation or diverse problem-solving approaches. This suggests that while GPT-3 models excel in narrow tasks, they struggle with open-ended, multi-step reasoning compared to humans.