TECHNICAL ASSET FINGERPRINT
592deb53a255c39cdf1cc8eb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
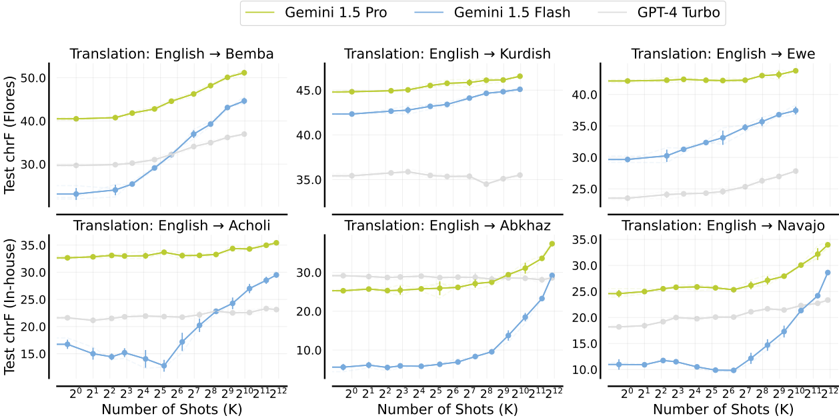
## Chart Type: Comparative Line Graphs of Translation Performance
### Overview
The image presents six line graphs comparing the performance of three language models (Gemini 1.5 Pro, Gemini 1.5 Flash, and GPT-4 Turbo) on English translation tasks into different target languages. The x-axis represents the number of shots (K), which is the number of examples used for training, and the y-axis represents the Test chrF score, a metric for translation quality. The graphs are arranged in a 2x3 grid, each focusing on a different target language.
### Components/Axes
* **Title:** Comparative Line Graphs of Translation Performance
* **Legend:** Located at the top of the image.
* Gemini 1.5 Pro (Yellow-Green)
* Gemini 1.5 Flash (Blue)
* GPT-4 Turbo (Light Gray)
* **X-axis:** Number of Shots (K). Logarithmic scale with base 2. Markers at 2^0, 2^1, 2^2, 2^3, 2^4, 2^5, 2^6, 2^7, 2^8, 2^9, 2^10, 2^11, 2^12.
* **Y-axis:** Test chrF.
* Top row (Flores): Scale from 30.0 to 50.0, with ticks at 30.0, 35.0, 40.0, 45.0, 50.0.
* Bottom row (In-house): Scale from 10.0 to 35.0, with ticks at 10.0, 15.0, 20.0, 25.0, 30.0, 35.0.
* **Titles of Subplots:**
* Translation: English -> Bemba
* Translation: English -> Kurdish
* Translation: English -> Ewe
* Translation: English -> Acholi
* Translation: English -> Abkhaz
* Translation: English -> Navajo
### Detailed Analysis
**Graph 1: English -> Bemba**
* Y-axis: Test chrF (Flores)
* Gemini 1.5 Pro (Yellow-Green): Starts at approximately 40.5 and increases to approximately 50.5.
* Gemini 1.5 Flash (Blue): Starts at approximately 23.5 and increases to approximately 41.0.
* GPT-4 Turbo (Light Gray): Starts at approximately 30.0 and increases to approximately 38.0.
**Graph 2: English -> Kurdish**
* Y-axis: Test chrF (Flores)
* Gemini 1.5 Pro (Yellow-Green): Starts at approximately 45.0 and increases slightly to approximately 46.5.
* Gemini 1.5 Flash (Blue): Starts at approximately 42.5 and increases slightly to approximately 44.5.
* GPT-4 Turbo (Light Gray): Starts at approximately 35.0 and fluctuates slightly, ending around 32.0.
**Graph 3: English -> Ewe**
* Y-axis: Test chrF (Flores)
* Gemini 1.5 Pro (Yellow-Green): Starts at approximately 41.5 and increases slightly to approximately 43.0.
* Gemini 1.5 Flash (Blue): Starts at approximately 30.0 and increases to approximately 37.5.
* GPT-4 Turbo (Light Gray): Starts at approximately 24.0 and increases to approximately 27.0.
**Graph 4: English -> Acholi**
* Y-axis: Test chrF (In-house)
* Gemini 1.5 Pro (Yellow-Green): Starts at approximately 33.5 and increases slightly to approximately 35.5.
* Gemini 1.5 Flash (Blue): Starts at approximately 17.0, dips to approximately 13.0, and then increases to approximately 30.0.
* GPT-4 Turbo (Light Gray): Starts at approximately 22.0 and fluctuates slightly, ending around 24.0.
**Graph 5: English -> Abkhaz**
* Y-axis: Test chrF (In-house)
* Gemini 1.5 Pro (Yellow-Green): Starts at approximately 28.0 and increases slightly to approximately 29.0.
* Gemini 1.5 Flash (Blue): Starts at approximately 5.0 and increases to approximately 32.0.
* GPT-4 Turbo (Light Gray): Starts at approximately 30.0 and fluctuates slightly, ending around 28.0.
**Graph 6: English -> Navajo**
* Y-axis: Test chrF (In-house)
* Gemini 1.5 Pro (Yellow-Green): Starts at approximately 25.0 and increases to approximately 34.0.
* Gemini 1.5 Flash (Blue): Starts at approximately 11.0, dips to approximately 9.0, and then increases to approximately 28.0.
* GPT-4 Turbo (Light Gray): Starts at approximately 20.0 and fluctuates slightly, ending around 22.0.
### Key Observations
* Gemini 1.5 Pro consistently performs well across all translation tasks, generally achieving the highest chrF scores.
* Gemini 1.5 Flash shows significant improvement with an increasing number of shots, particularly in the "In-house" datasets (Acholi, Abkhaz, Navajo).
* GPT-4 Turbo's performance is relatively stable across different numbers of shots, but it generally scores lower than Gemini 1.5 Pro and, in many cases, lower than Gemini 1.5 Flash with sufficient shots.
* The "Flores" datasets (Bemba, Kurdish, Ewe) generally yield higher chrF scores compared to the "In-house" datasets (Acholi, Abkhaz, Navajo).
* The performance of Gemini 1.5 Flash on Acholi and Navajo translation tasks initially decreases before increasing with more shots.
### Interpretation
The data suggests that Gemini 1.5 Pro is a strong performer for English translation across various languages, demonstrating high accuracy even with limited training examples. Gemini 1.5 Flash benefits significantly from increased training data, eventually approaching or even surpassing GPT-4 Turbo's performance in some cases. GPT-4 Turbo provides a baseline level of performance that is relatively consistent regardless of the number of training examples.
The difference in chrF scores between the "Flores" and "In-house" datasets may indicate variations in the complexity or quality of the datasets themselves. The initial dip in performance for Gemini 1.5 Flash on Acholi and Navajo translation tasks could be due to overfitting or other optimization challenges at lower shot counts.
Overall, the graphs highlight the importance of model selection and training data size for achieving optimal translation performance. Gemini 1.5 Pro appears to be a robust choice, while Gemini 1.5 Flash can be a viable alternative with sufficient training data.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Graphs: Test ChrF (Floores/In-house) vs. Number of Shots (K) for Translation Tasks
### Overview
The image contains six line graphs comparing the performance of three AI models (Gemini 1.5 Pro, Gemini 1.5 Flash, GPT-4 Turbo) across six translation tasks (English → Bemba, Kurdish, Ewe, Acholi, Abkhaz, Navajo). Each graph plots **Test ChrF** (a metric for translation quality) against **Number of Shots (K)**, where K represents the amount of training data used (e.g., 2^1 = 2 examples, 2^12 = 4096 examples). The graphs are arranged in two rows of three, with legends at the top indicating model colors: yellow (Gemini 1.5 Pro), blue (Gemini 1.5 Flash), gray (GPT-4 Turbo).
---
### Components/Axes
- **X-axis**: Number of Shots (K) on a logarithmic scale (2^1 to 2^12).
- **Y-axis**: Test ChrF (Floores/In-house), with values ranging from ~10 to 50 depending on the task.
- **Legends**: Positioned at the top of all graphs, with consistent color coding:
- Yellow: Gemini 1.5 Pro
- Blue: Gemini 1.5 Flash
- Gray: GPT-4 Turbo
- **Subplot Titles**: Each graph is labeled with the translation direction (e.g., "Translation: English → Bemba").
---
### Detailed Analysis
#### 1. Translation: English → Bemba
- **Trend**: Gemini 1.5 Pro (yellow) shows a steep upward slope, reaching ~50 Floores at 2^12 shots. Gemini 1.5 Flash (blue) increases from ~30 to ~45, while GPT-4 Turbo (gray) remains flat (~30–35).
- **Key Data Points**:
- At 2^1 shots: Gemini 1.5 Pro ≈ 40, Gemini 1.5 Flash ≈ 30, GPT-4 Turbo ≈ 30.
- At 2^12 shots: Gemini 1.5 Pro ≈ 50, Gemini 1.5 Flash ≈ 45, GPT-4 Turbo ≈ 35.
#### 2. Translation: English → Kurdish
- **Trend**: Gemini 1.5 Pro (yellow) rises from ~40 to ~45, Gemini 1.5 Flash (blue) increases from ~35 to ~42, and GPT-4 Turbo (gray) stays flat (~30–35).
- **Key Data Points**:
- At 2^1 shots: Gemini 1.5 Pro ≈ 40, Gemini 1.5 Flash ≈ 35, GPT-4 Turbo ≈ 30.
- At 2^12 shots: Gemini 1.5 Pro ≈ 45, Gemini 1.5 Flash ≈ 42, GPT-4 Turbo ≈ 35.
#### 3. Translation: English → Ewe
- **Trend**: Gemini 1.5 Pro (yellow) increases from ~40 to ~45, Gemini 1.5 Flash (blue) rises from ~30 to ~38, and GPT-4 Turbo (gray) remains flat (~25–30).
- **Key Data Points**:
- At 2^1 shots: Gemini 1.5 Pro ≈ 40, Gemini 1.5 Flash ≈ 30, GPT-4 Turbo ≈ 25.
- At 2^12 shots: Gemini 1.5 Pro ≈ 45, Gemini 1.5 Flash ≈ 38, GPT-4 Turbo ≈ 30.
#### 4. Translation: English → Acholi
- **Trend**: Gemini 1.5 Pro (yellow) increases from ~30 to ~35, Gemini 1.5 Flash (blue) rises from ~15 to ~30, and GPT-4 Turbo (gray) stays flat (~20–25).
- **Key Data Points**:
- At 2^1 shots: Gemini 1.5 Pro ≈ 30, Gemini 1.5 Flash ≈ 15, GPT-4 Turbo ≈ 20.
- At 2^12 shots: Gemini 1.5 Pro ≈ 35, Gemini 1.5 Flash ≈ 30, GPT-4 Turbo ≈ 25.
#### 5. Translation: English → Abkhaz
- **Trend**: Gemini 1.5 Pro (yellow) increases from ~25 to ~35, Gemini 1.5 Flash (blue) rises from ~10 to ~30, and GPT-4 Turbo (gray) remains flat (~20–25).
- **Key Data Points**:
- At 2^1 shots: Gemini 1.5 Pro ≈ 25, Gemini 1.5 Flash ≈ 10, GPT-4 Turbo ≈ 20.
- At 2^12 shots: Gemini 1.5 Pro ≈ 35, Gemini 1.5 Flash ≈ 30, GPT-4 Turbo ≈ 25.
#### 6. Translation: English → Navajo
- **Trend**: Gemini 1.5 Pro (yellow) increases from ~25 to ~35, Gemini 1.5 Flash (blue) rises from ~10 to ~30, and GPT-4 Turbo (gray) stays flat (~20–25).
- **Key Data Points**:
- At 2^1 shots: Gemini 1.5 Pro ≈ 25, Gemini 1.5 Flash ≈ 10, GPT-4 Turbo ≈ 20.
- At 2^12 shots: Gemini 1.5 Pro ≈ 35, Gemini 1.5 Flash ≈ 30, GPT-4 Turbo ≈ 25.
---
### Key Observations
1. **Model Performance**:
- **Gemini 1.5 Pro** consistently outperforms other models across all tasks, with the largest gains at higher shot counts (e.g., +10 Floores from 2^1 to 2^12 in Bemba).
- **Gemini 1.5 Flash** shows moderate improvement, with gains of ~10–15 Floores across tasks.
- **GPT-4 Turbo** performs the least effectively, with minimal improvement (often flat lines).
2. **Task-Specific Trends**:
- **Low-Resource Languages** (e.g., Abkhaz, Navajo): Gemini 1.5 Pro and Flash show steeper improvement curves, suggesting better scalability with limited data.
- **High-Resource Languages** (e.g., Kurdish, Ewe): GPT-4 Turbo maintains higher baseline performance but fails to scale.
3. **Anomalies**:
- In **English → Acholi**, Gemini 1.5 Flash shows a sharp dip at 2^3 shots (~12 Floores) before recovering, possibly indicating overfitting or data noise.
---
### Interpretation
The data demonstrates that **Gemini 1.5 Pro** excels in translation quality, particularly when trained on larger datasets (higher K values). Its performance scales nearly linearly with the number of shots, suggesting robust generalization. **Gemini 1.5 Flash** also improves with more data but lags behind the Pro version, likely due to architectural differences (e.g., smaller model size). **GPT-4 Turbo** performs poorly in low-resource scenarios (e.g., Abkhaz, Navajo) but maintains mediocre results in high-resource tasks, indicating limited adaptability to new languages.
The stark contrast between Gemini models and GPT-4 Turbo highlights the importance of model architecture and training strategies for cross-lingual tasks. The dip in Gemini 1.5 Flash for Acholi warrants further investigation into data quality or model stability. Overall, these results underscore the value of iterative training with increasing data volumes for low-resource language translation.
DECODING INTELLIGENCE...