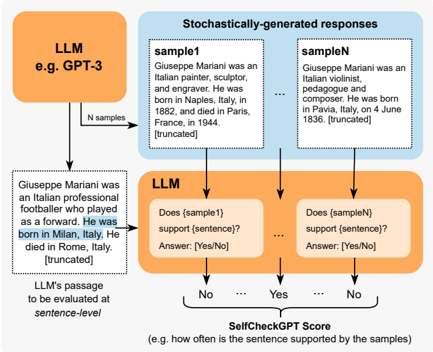
## Flowchart: LLM Evaluation Process with Stochastic Samples
### Overview
The image depicts a flowchart illustrating how a Large Language Model (LLM), such as GPT-3, evaluates the validity of a generated sentence using stochastically produced samples. The process involves generating multiple samples, comparing them to a target sentence, and assigning a "SelfCheckGPT Score" based on consistency.
---
### Components/Axes
1. **Key Elements**:
- **LLM (e.g., GPT-3)**: Central node initiating the process.
- **Stochastically-generated responses**: Box containing multiple samples (e.g., `sample1`, `sampleN`).
- **Evaluation Questions**: Nodes asking whether samples support a specific sentence (e.g., "Does {sample1} support {sentence}?").
- **SelfCheckGPT Score**: Final output indicating the frequency of sample support for the sentence.
2. **Flow Direction**:
- Arrows indicate sequential steps: LLM → Sample Generation → Evaluation → Scoring.
3. **Textual Content**:
- **Sample1**: "Giuseppe Mariani was an Italian painter, sculptor, and engraver. He was born in Naples, Italy, in 1882, and died in Paris, France, in 1944."
- **SampleN**: "Giuseppe Mariani was an Italian violinist, pedagogue, and composer. He was born in Pavia, Italy, on 4 June 1836."
- **Target Sentence**: "Giuseppe Mariani was an Italian professional footballer who played as a forward. He was born in Milan, Italy."
---
### Detailed Analysis
1. **Sample Generation**:
- The LLM generates `N` samples (e.g., `sample1`, `sampleN`) with varying factual details about Giuseppe Mariani. These samples contain conflicting information (e.g., birth/death locations, professions).
2. **Evaluation Process**:
- The LLM evaluates each sample against a target sentence using yes/no questions (e.g., "Does {sample1} support {sentence}?").
- Responses are binary (Yes/No), with uncertainty implied by truncation (e.g., "[truncated]").
3. **Scoring Mechanism**:
- The **SelfCheckGPT Score** quantifies how often the sentence is supported by the samples (e.g., "how often is the sentence supported by the samples?").
---
### Key Observations
1. **Conflicting Information**:
- Samples contain contradictory facts about Giuseppe Mariani (e.g., birth in Naples vs. Pavia, professions as painter vs. violinist).
- The target sentence introduces a new claim (footballer born in Milan) not present in any sample.
2. **Truncation**:
- All samples and the target sentence are truncated, suggesting incomplete or abbreviated outputs.
3. **Flowchart Structure**:
- The process is linear but repetitive, with multiple evaluation steps for each sample.
---
### Interpretation
1. **Purpose**:
- The flowchart demonstrates a self-evaluation mechanism for LLMs, where generated samples act as a consistency check for factual claims. This helps identify hallucinations or inaccuracies in the model's outputs.
2. **Mechanism**:
- By comparing the target sentence to diverse samples, the LLM assesses whether the claim aligns with plausible variations of the subject. A high score indicates strong consistency, while a low score flags potential errors.
3. **Notable Anomalies**:
- The target sentence introduces a completely new profession (footballer) and birthplace (Milan), which are absent in all samples. This would likely result in a low SelfCheckGPT Score, highlighting the model's ability to detect unsupported claims.
4. **Implications**:
- The process emphasizes the importance of cross-verification in AI-generated content, ensuring outputs are grounded in plausible or verified information.
---
### Conclusion
This flowchart illustrates a robust method for evaluating LLM-generated text by leveraging stochastic sampling and self-consistency checks. It underscores the challenges of factual accuracy in AI systems and provides a framework for improving reliability through iterative validation.