## Diagram: SelfCheckGPT Score Calculation
### Overview
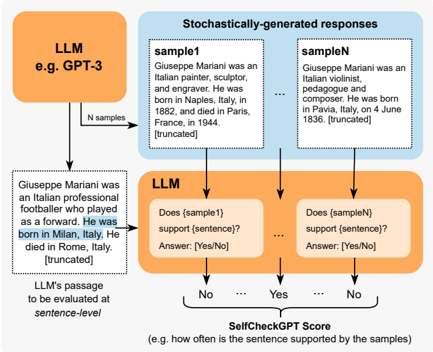
The image is a diagram illustrating how the SelfCheckGPT score is calculated. It shows the process of generating responses using a Large Language Model (LLM), evaluating a passage at the sentence level, and determining how often the sentence is supported by the generated samples.
### Components/Axes
* **Top-Left:** "LLM e.g. GPT-3" (orange box) - Represents the Large Language Model used to generate responses.
* **Top-Center:** "Stochastically-generated responses" (light blue box) - Represents the set of responses generated by the LLM.
* "sample1": Contains a truncated text about Giuseppe Mariani as an Italian painter, sculptor, and engraver.
* "sampleN": Contains a truncated text about Giuseppe Mariani as an Italian violinist, pedagogue, and composer.
* **Left:** "Giuseppe Mariani was an Italian professional footballer who played as a forward. He was born in Milan, Italy. He died in Rome, Italy. [truncated]" (dashed box) - Represents the passage being evaluated. The phrase "born in Milan, Italy" is highlighted in blue.
* "LLM's passage to be evaluated at sentence-level" - Label below the passage.
* **Center:** "LLM" (orange box) - Represents the LLM being used to evaluate the generated samples.
* "Does {sample1} support {sentence}?" and "Does {sampleN} support {sentence}?" - Questions posed to the LLM.
* "Answer: [Yes/No]" - Possible answers from the LLM.
* **Bottom:** "SelfCheckGPT Score (e.g. how often is the sentence supported by the samples)" - Represents the final score calculated based on the LLM's responses.
* **Arrows:** Arrows indicate the flow of information from the LLM to the stochastically generated responses, then to the LLM evaluation, and finally to the SelfCheckGPT score.
### Detailed Analysis
* The diagram starts with an LLM (e.g., GPT-3) that generates "N samples" of responses.
* These responses are represented by "sample1" to "sampleN," each containing a short, truncated text.
* A passage about Giuseppe Mariani is evaluated at the sentence level. The sentence "He was born in Milan, Italy" is highlighted.
* The LLM then evaluates whether each sample supports the sentence from the passage.
* The LLM provides a "Yes" or "No" answer for each sample.
* The SelfCheckGPT score is calculated based on how often the sentence is supported by the samples.
### Key Observations
* The diagram illustrates a process for evaluating the consistency and reliability of LLM-generated text.
* The SelfCheckGPT score provides a quantitative measure of how well the LLM's generated responses align with a given passage.
* The highlighting of "born in Milan, Italy" suggests that this specific sentence is the focus of the evaluation.
### Interpretation
The diagram depicts a method for assessing the factual accuracy and consistency of LLM-generated content. By generating multiple responses and then evaluating whether those responses support a specific sentence from a reference passage, the SelfCheckGPT score provides an indication of the LLM's reliability. This process is valuable for identifying potential biases, hallucinations, or inconsistencies in LLM outputs, ultimately contributing to the development of more trustworthy and accurate AI systems. The highlighting of a specific sentence indicates that the evaluation is performed at a granular level, allowing for a more precise assessment of the LLM's performance.