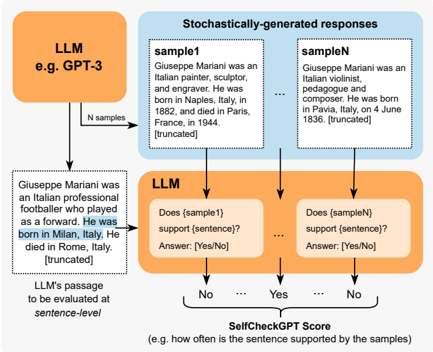
## Diagram: SelfCheckGPT Process Flow
### Overview
The image is a technical flowchart illustrating the "SelfCheckGPT" method, a technique for evaluating the factual consistency of a sentence generated by a Large Language Model (LLM). The process involves generating multiple stochastic samples from the LLM and then using the LLM itself to check if each sample supports the original sentence. The final output is a score representing the proportion of supporting samples.
### Components/Axes
The diagram is structured as a process flow with distinct, color-coded components connected by directional arrows.
**1. Primary Input (Left, Orange Box):**
* **Label:** `LLM e.g. GPT-3`
* **Content:** A text passage to be evaluated.
* **Text:** "Giuseppe Mariani was an Italian professional footballer who played as a forward. He was born in Milan, Italy. He died in Rome, Italy. [truncated]"
* **Annotation:** "LLM's passage to be evaluated at *sentence-level*"
**2. Sampling Stage (Top, Blue Box):**
* **Title:** `Stochastically-generated responses`
* **Components:** Multiple sample boxes.
* **`sample1` Box:** "Giuseppe Mariani was an Italian painter, sculptor and engraver. He was born in Naples, Italy, in 1888 and died in Paris, France, in 1944. [truncated]"
* **Ellipsis (`...`):** Indicates multiple intermediate samples.
* **`sampleN` Box:** "Giuseppe Mariani was an Italian artist, pedagogue and composer. He was born in Naples, Italy, on 4 June 1836. [truncated]"
* **Flow:** An arrow labeled "N samples" points from the primary LLM box to this sampling stage.
**3. Evaluation Stage (Bottom, Green Box):**
* **Label:** `LLM`
* **Components:** Multiple evaluation boxes, one per sample.
* **First Evaluation Box:** "Does {sample1} support {sentence}? Answer: {Yes/No}"
* **Ellipsis (`...`):** Indicates evaluations for all samples.
* **Last Evaluation Box:** "Does {sampleN} support {sentence}? Answer: {Yes/No}"
* **Flow:** Arrows point from each sample box and from the primary sentence to their respective evaluation boxes.
**4. Aggregation & Output (Bottom, Text):**
* **Label:** `SelfCheckGPT Score`
* **Content:** "e.g. how often the sentence is supported by the samples"
* **Flow:** Arrows from the evaluation boxes (labeled "No", "Yes", "...", "No") point to this final score calculation.
### Detailed Analysis
The diagram explicitly details a five-step process:
1. **Input:** A specific sentence (about Giuseppe Mariani being a footballer born in Milan) is produced by an LLM (e.g., GPT-3).
2. **Sampling:** The same LLM is prompted to generate `N` different, independent responses (samples) about the same entity (Giuseppe Mariani). The provided samples contain contradictory information (painter vs. artist, different birthplaces and dates).
3. **Pairwise Evaluation:** For each generated sample, the LLM is queried to determine if that sample *supports* the factual claim in the original sentence. This is a binary (Yes/No) judgment.
4. **Scoring:** The SelfCheckGPT Score is calculated as the frequency (proportion) of "Yes" answers across all `N` evaluations. In the visual example, two "No" votes are shown, suggesting a low support score for the original sentence.
### Key Observations
* **Contradictory Samples:** The provided `sample1` and `sampleN` directly contradict the original sentence's core claims (footballer vs. painter/artist; Milan vs. Naples; different life dates). This visually demonstrates the method's purpose: to detect when an LLM's initial output is not supported by its own stochastic generations.
* **Truncation Noted:** All text passages are marked as `[truncated]`, indicating they are excerpts from longer generated texts.
* **Self-Referential Evaluation:** The same LLM architecture is used for both generation and evaluation, which is the core innovation of the SelfCheckGPT method.
* **Spatial Layout:** The flow is clearly top-to-bottom and left-to-right. The legend is implicit through color-coding: Orange (Primary LLM I/O), Blue (Sampling Process), Green (Evaluation Process).
### Interpretation
This diagram explains a **self-supervised fact-checking mechanism for LLMs**. The underlying principle is that if a sentence generated by an LLM is factually consistent and reliable, then other random samples from the same model about the same topic should tend to agree with it. Conversely, if the initial sentence is a "hallucination" (fabricated or incorrect), the stochastic samples will likely contain contradictions, leading to a low SelfCheckGPT Score.
The method is significant because it provides a way to estimate the factual accuracy of an LLM's output **without requiring an external knowledge base or ground-truth data**. It leverages the model's own distribution of possible outputs as a reference. The example chosen—a historical figure with conflicting attributes—perfectly illustrates a scenario where this technique would flag the original sentence as potentially unreliable. The "sentence-level" annotation suggests the evaluation can be granular, assessing individual claims within a larger text.