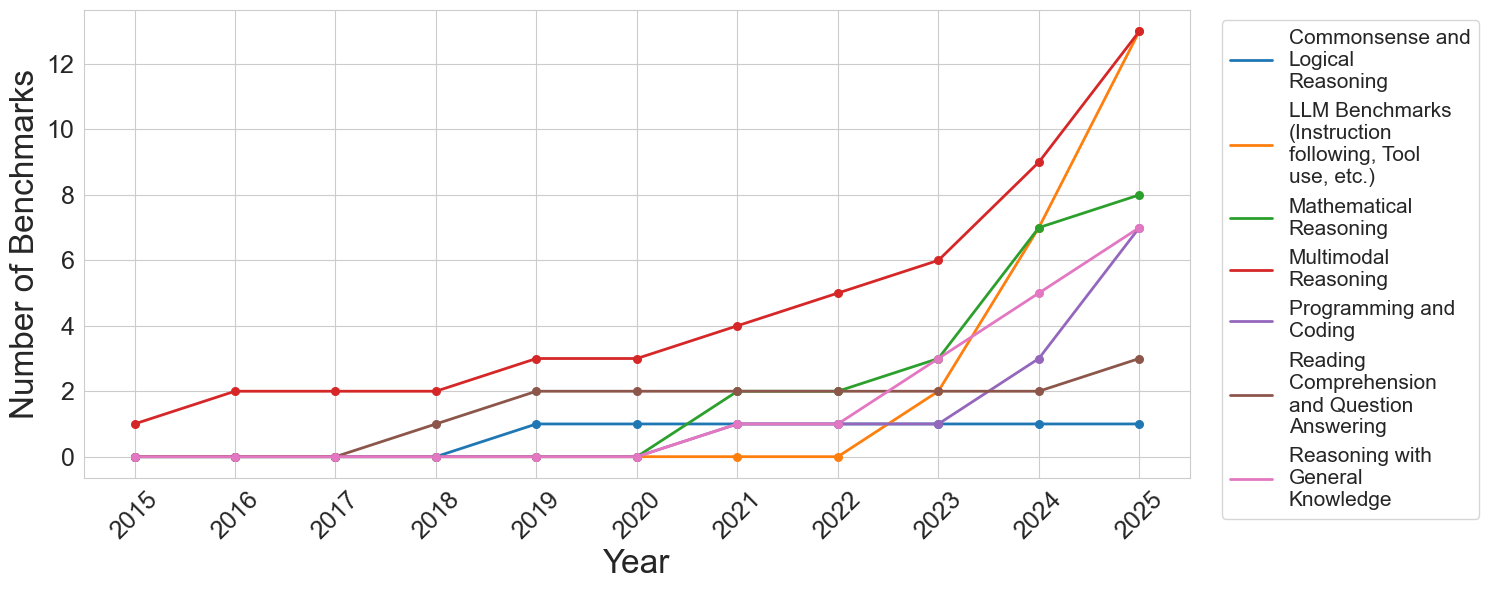
## Line Chart: Growth of LLM Benchmarks by Category (2015-2025)
### Overview
This line chart depicts the number of benchmarks available for Large Language Models (LLMs) across various reasoning categories from 2015 to 2025 (projected). The chart shows a general upward trend in the total number of benchmarks, with significant growth in certain categories towards the end of the period. The legend is positioned in the top-right corner of the chart.
### Components/Axes
* **X-axis:** Year (ranging from 2015 to 2025, with increments of 1 year).
* **Y-axis:** Number of Benchmarks (ranging from 0 to 12, with increments of 2).
* **Legend:** Located in the top-right corner, listing the following categories with corresponding colors:
* Commonsense and Logical Reasoning (Blue)
* LLM Benchmarks (Instruction following, Tool use, etc.) (Orange)
* Mathematical Reasoning (Green)
* Multimodal Reasoning (Purple)
* Programming and Coding (Teal)
* Reading Comprehension and Question Answering (Red)
* Reasoning with General Knowledge (Gray)
### Detailed Analysis
Here's a breakdown of each data series, with approximate values:
* **Commonsense and Logical Reasoning (Blue):** The line is relatively flat from 2015 to 2022, hovering around 1-2 benchmarks. It shows a slight increase from 2022 to 2024, reaching approximately 3 benchmarks, and then a more significant jump to around 4 benchmarks in 2025.
* **LLM Benchmarks (Instruction following, Tool use, etc.) (Orange):** This line exhibits the most dramatic growth. Starting at approximately 1 benchmark in 2015, it steadily increases to around 4 benchmarks in 2020. From 2020 to 2025, the growth accelerates, reaching approximately 12 benchmarks in 2025.
* **Mathematical Reasoning (Green):** The line starts at approximately 0 benchmarks in 2015 and gradually increases to around 2 benchmarks by 2019. It remains relatively stable until 2023, then shows a steeper increase, reaching approximately 8 benchmarks in 2025.
* **Multimodal Reasoning (Purple):** This line begins at 0 benchmarks in 2015 and remains at 0 until 2020. It then increases steadily, reaching approximately 5 benchmarks in 2025.
* **Programming and Coding (Teal):** The line starts at approximately 0 benchmarks in 2015 and increases to around 2 benchmarks by 2018. It fluctuates between 2 and 3 benchmarks until 2023, then increases to approximately 6 benchmarks in 2025.
* **Reading Comprehension and Question Answering (Red):** This line starts at approximately 1 benchmark in 2015 and increases to around 3 benchmarks by 2019. It remains relatively stable until 2024, then increases to approximately 5 benchmarks in 2025.
* **Reasoning with General Knowledge (Gray):** The line is consistently low, starting at approximately 1 benchmark in 2015 and remaining around 1-2 benchmarks throughout the entire period, reaching approximately 2 benchmarks in 2025.
### Key Observations
* The number of LLM benchmarks has increased significantly over the past decade, particularly in the last few years.
* "LLM Benchmarks (Instruction following, Tool use, etc.)" shows the most substantial growth, indicating a growing focus on evaluating these capabilities.
* "Mathematical Reasoning" and "Multimodal Reasoning" have experienced significant growth in the later years (2023-2025).
* "Reasoning with General Knowledge" remains relatively stable, suggesting a slower pace of development in this area.
* The growth in benchmarks appears to be accelerating towards 2025, suggesting continued investment and innovation in LLM evaluation.
### Interpretation
The data suggests a rapid expansion in the evaluation landscape for LLMs. The increasing number of benchmarks across various reasoning categories indicates a growing need to comprehensively assess the capabilities of these models. The significant growth in "LLM Benchmarks (Instruction following, Tool use, etc.)" reflects the increasing importance of evaluating LLMs' ability to follow instructions and utilize tools. The recent surge in "Mathematical Reasoning" and "Multimodal Reasoning" benchmarks suggests a growing focus on these challenging areas. The relatively stable number of "Reasoning with General Knowledge" benchmarks might indicate that this area is considered relatively mature or that evaluating it is more difficult.
The overall trend suggests that the field of LLM evaluation is becoming more sophisticated and nuanced, with a greater emphasis on assessing a wider range of capabilities. This is likely driven by the increasing power and complexity of LLMs, as well as the growing demand for reliable and trustworthy AI systems. The projected growth towards 2025 indicates that this trend is likely to continue, with even more benchmarks being developed to evaluate the next generation of LLMs.