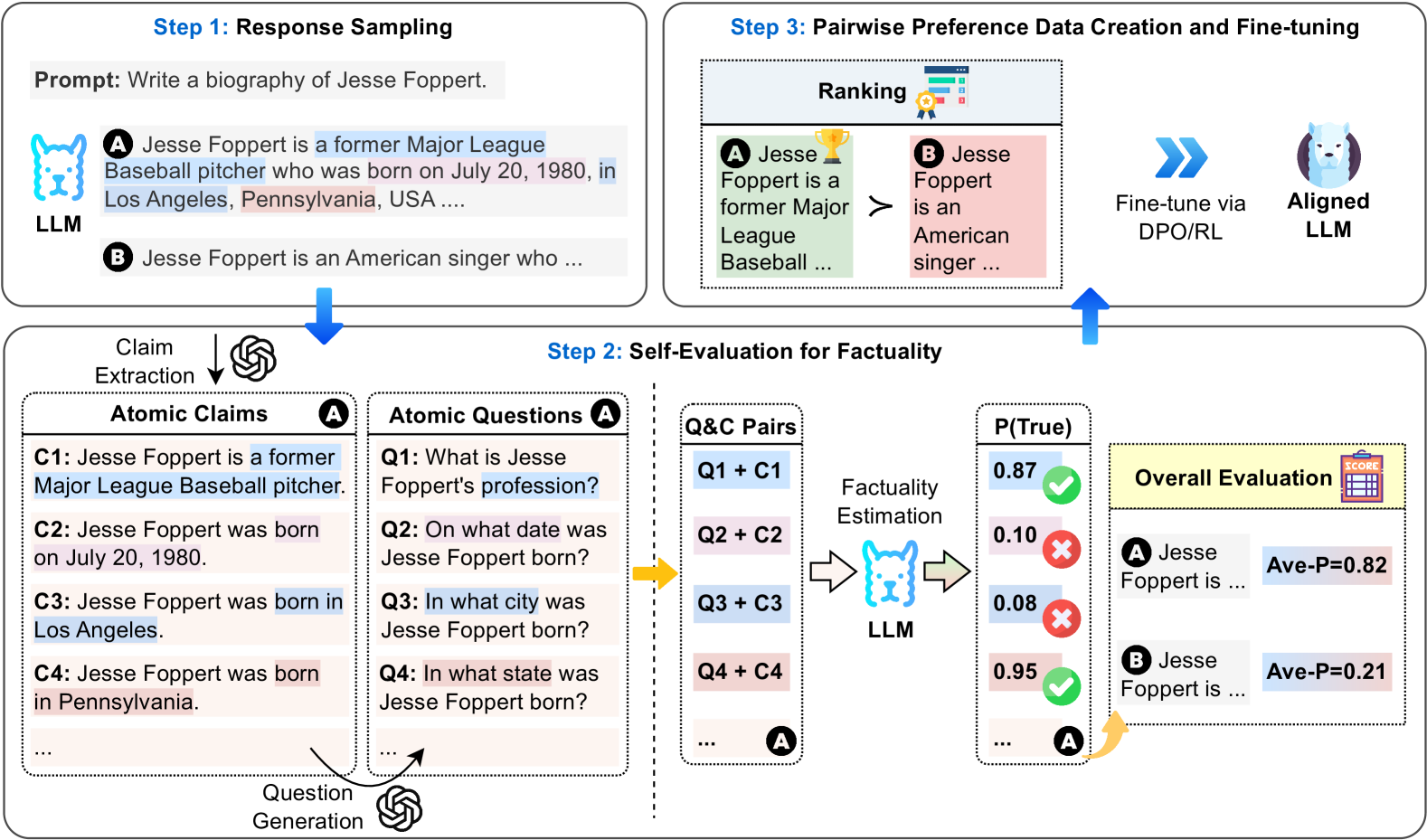
## Diagram: Aligned LLM Training Pipeline
### Overview
This diagram illustrates a three-step pipeline for training an Aligned Large Language Model (LLM). The steps are: Response Sampling, Self-Evaluation for Factuality, and Pairwise Preference Data Creation & Fine-tuning. The diagram visually represents the flow of information and the processes involved in each step, aiming to create an LLM that is both informative and factually accurate.
### Components/Axes
The diagram is segmented into three main steps, each with its own visual representation and associated text. The steps are numbered 1, 2, and 3, and are arranged horizontally across the image. There are several key components within each step:
* **Step 1: Response Sampling:** Includes a "Prompt" box and two LLM outputs labeled "A" and "B".
* **Step 2: Self-Evaluation for Factuality:** Contains "Claim Extraction", "Atomic Questions", "Q&A Pairs", "Factuality Estimation", and "Overall Evaluation" sections. A probability value, P(True), is displayed for each Q&A pair.
* **Step 3: Pairwise Preference Data Creation & Fine-tuning:** Includes a "Ranking" section with a visual preference indicator (yellow arrow), and a "Fine-tune via DPO/RL" box leading to an "Aligned LLM".
* **Labels:** "LLM", "Aligned LLM", "Prompt", "Ranking", "Factuality Estimation", "Overall Evaluation", "Atomic Claims", "Atomic Questions", "Q&A Pairs".
* **Color Coding:** "A" responses are consistently colored blue, while "B" responses are colored orange. This color scheme is maintained throughout the diagram.
### Detailed Analysis or Content Details
**Step 1: Response Sampling**
* **Prompt:** "Write a biography of Jesse Foppert."
* **LLM Response A:** "Jesse Foppert is a former Major League Baseball pitcher who was born on July 20, 1980, in Los Angeles, Pennsylvania, USA..."
* **LLM Response B:** "Jesse Foppert is an American singer who..."
**Step 2: Self-Evaluation for Factuality**
* **Claim Extraction:**
* C1: Jesse Foppert is a former Major League Baseball pitcher.
* C2: Jesse Foppert was born on July 20, 1980.
* C3: Jesse Foppert was born in Los Angeles.
* C4: Jesse Foppert was born in Pennsylvania.
* **Atomic Questions:**
* Q1: What is Jesse Foppert's profession?
* Q2: On what date was Jesse Foppert born?
* Q3: In what city was Jesse Foppert born?
* Q4: In what state was Jesse Foppert born?
* **Q&A Pairs & P(True) Values:**
* Q1 + C1: P(True) = 0.87
* Q2 + C2: P(True) = 0.10
* Q3 + C3: P(True) = 0.08
* Q4 + C4: P(True) = 0.95
* **Overall Evaluation:**
* Response A: Ave-P = 0.82
* Response B: Ave-P = 0.21
**Step 3: Pairwise Preference Data Creation & Fine-tuning**
* **Ranking:** A yellow arrow points from Response A to Response B, indicating a preference for Response A. The text states "Jesse Foppert is a former Major League Baseball..." is preferred over "Jesse Foppert is an American singer...".
* **Fine-tuning:** "Fine-tune via DPO/RL" leads to an "Aligned LLM".
### Key Observations
* Response A consistently receives higher factuality scores (P(True) and Ave-P) than Response B.
* The factuality estimation for the birthdate (Q2 + C2) and city (Q3 + C3) of Jesse Foppert is very low for Response A, suggesting inaccuracies in that response.
* The ranking step clearly favors Response A, likely due to its higher overall factuality score.
* The pipeline aims to refine the LLM through a process of self-evaluation and preference learning.
### Interpretation
This diagram illustrates a Reinforcement Learning from Human Feedback (RLHF) or Direct Preference Optimization (DPO) approach to aligning an LLM with factual accuracy. The process begins with generating multiple responses to a prompt. These responses are then subjected to a factuality check, broken down into atomic claims and questions. The LLM itself estimates the probability of each claim being true. Based on these estimations, an overall evaluation is performed, and a preference is established between the responses. Finally, this preference data is used to fine-tune the LLM, guiding it towards generating more factual and reliable outputs.
The low P(True) values for the birthdate and city in Response A suggest that while the overall topic (Jesse Foppert being a baseball player) is accurate, the specific details are incorrect. This highlights the importance of granular factuality checks. The diagram demonstrates a sophisticated approach to LLM training that goes beyond simply maximizing likelihood and focuses on aligning the model with human values of truthfulness and accuracy. The use of DPO/RL suggests a preference-based learning approach, where the model learns from comparisons between responses rather than explicit rewards.