## Line Chart: Learning Rate Schedule
### Overview
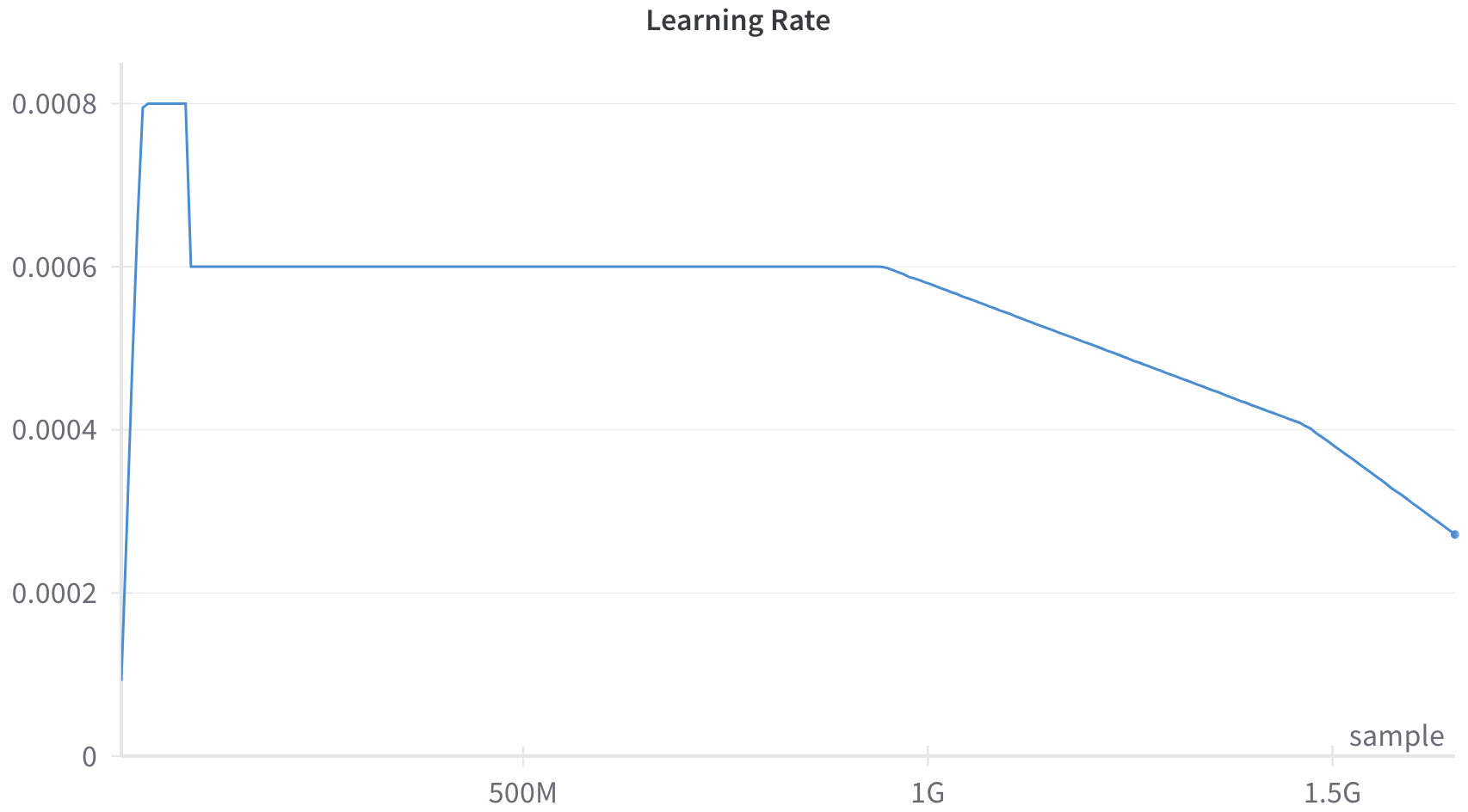
This image is a line chart displaying a "Learning Rate" schedule over a number of training samples. The chart features a single blue line that illustrates a specific learning rate strategy, characterized by an initial sharp warmup, a brief peak, a step-down to a sustained plateau, and a final linear decay phase. All text in the image is in English.
### Components/Axes
**Header Region:**
* **Title:** "Learning Rate" (Located top-center, dark gray text).
**Main Chart Region:**
* **Data Series:** A single solid blue line representing the learning rate value. It ends with a distinct blue circular marker (dot) at the final data point.
* **Grid:** Four light gray horizontal grid lines corresponding to the Y-axis major tick marks (excluding 0). There are no vertical grid lines.
* **Legend:** There is no legend present, as there is only a single data series.
**Axes/Footer Region:**
* **Y-axis (Left):** Represents the learning rate value. It has a solid light gray axis line.
* **Markers (Bottom to Top):** `0`, `0.0002`, `0.0004`, `0.0006`, `0.0008`.
* **Label:** There is no explicit Y-axis label, though the chart title "Learning Rate" serves this purpose.
* **X-axis (Bottom):** Represents the number of samples processed. It has a solid light gray axis line with small vertical tick marks.
* **Markers (Left to Right):**
* [Origin]: Implicitly 0.
* `500M` (Located at approximately 30% of the axis width).
* `1G` (Located at approximately 60% of the axis width).
* `1.5G` (Located at approximately 90% of the axis width).
* **Label:** "sample" (Located at the bottom-right, just above the X-axis line).
* *Note on scale:* 'M' denotes Millions, and 'G' denotes Billions (Giga).
### Detailed Analysis
**Trend Verification and Data Extraction:**
The single blue line exhibits four distinct phases.
1. **Warmup Phase (Steep Upward Slope):**
* *Trend:* The line starts slightly above zero and slopes upward almost vertically.
* *Data Points:* Starts at X = 0, Y ≈ 0.0001. It rises sharply to reach Y = 0.0008 at an estimated X ≈ 50M.
2. **Peak Phase (Flat Horizontal Line):**
* *Trend:* The line remains perfectly flat at its maximum value for a brief period.
* *Data Points:* Maintains Y = 0.0008 from X ≈ 50M to X ≈ 100M.
3. **Plateau Phase (Step-down and Flat Horizontal Line):**
* *Trend:* The line drops vertically, then remains perfectly flat for the majority of the chart.
* *Data Points:* At X ≈ 100M, the value drops sharply from Y = 0.0008 to Y = 0.0006. It then holds steady at Y = 0.0006 across the 500M mark, continuing until just before the 1G mark (estimated X ≈ 950M).
4. **Decay Phase (Downward Linear Slope):**
* *Trend:* The line slopes downward at a constant, linear rate until the end of the chart.
* *Data Points:* The decay begins at X ≈ 950M, Y = 0.0006. It crosses exactly through the grid intersection at X = 1.5G, Y = 0.0004. The line terminates with a distinct dot at an estimated X ≈ 1.75G, with a final Y-value of approximately 0.00027.
### Key Observations
* **Anomalous Step-Down:** Unlike standard cosine or linear decay schedules that smoothly transition from a peak, this schedule features a hard, instantaneous step-down from 0.0008 to 0.0006 early in the training process.
* **Extended Constant Rate:** The vast majority of the training (from ~100M to ~950M samples) occurs at a static learning rate of 0.0006.
* **Linear Decay:** The final phase is strictly linear, rather than curved (exponential or cosine), dropping by exactly 0.0002 over the course of roughly 550M samples (from ~950M to 1.5G).
### Interpretation
This chart represents a highly specific, custom learning rate schedule used for training a machine learning model (likely a large neural network, given the scale of billions of samples).
* **The Warmup:** The initial spike to 0.0008 is a standard "warmup" phase. This prevents the model's weights from diverging early in training when gradients are large and unstable.
* **The Step-Down & Plateau:** The sudden drop to 0.0006 and the long plateau suggest a deliberate design choice. The engineers likely found that 0.0008 was too high for sustained training (perhaps causing instability after the initial warmup), but 0.0006 provided a stable, rapid convergence rate for the bulk of the training process.
* **The Linear Decay:** The linear decay starting near 1 Billion samples represents the "fine-tuning" or "annealing" phase. As the model gets closer to an optimal solution, the learning rate is steadily reduced so the model can settle into a local minimum without overshooting it.
* **Incomplete Run:** The presence of the dot at the end of the line, combined with the fact that the learning rate has not reached zero, implies that this chart represents a snapshot of a training run that either finished at exactly ~1.75G samples, or was paused/evaluated at that specific point.