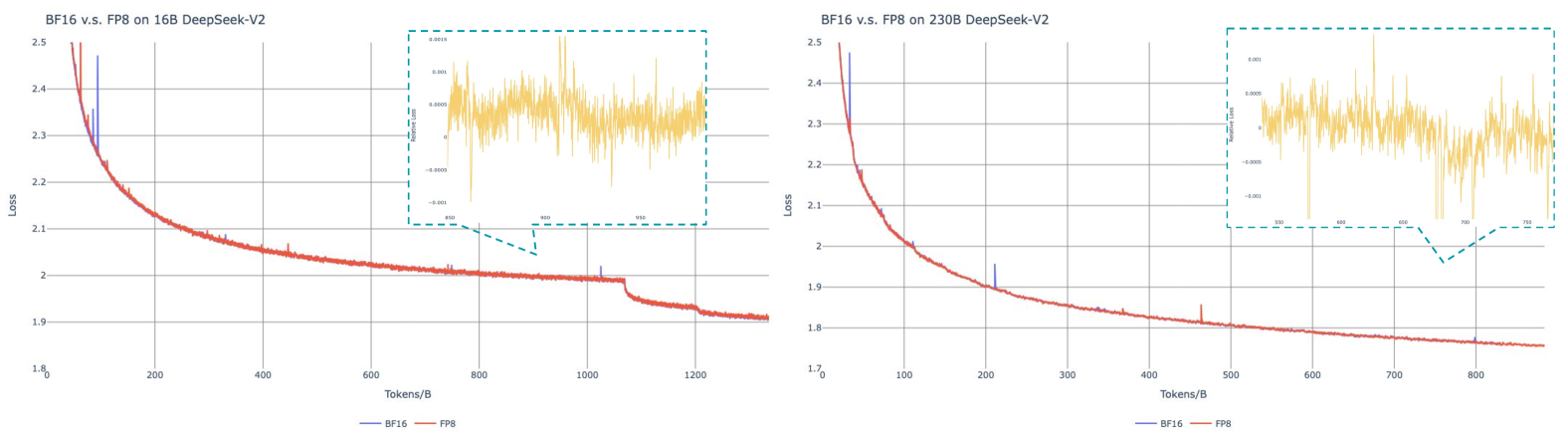
# Technical Analysis of BF16 vs FP8 Performance on DeepSeek-V2 Models
## Chart 1: BF16 vs FP8 on 16B DeepSeek-V2
- **Title**: "BF16 v.s. FP8 on 16B DeepSeek-V2"
- **X-axis**: "Tokens/B" (range: 0–1200)
- **Y-axis**: "Loss" (range: 1.8–2.5)
- **Legend**:
- Blue line: BF16
- Orange line: FP8
- **Key Observations**:
- Both BF16 and FP8 show a sharp initial decline in loss, followed by a gradual plateau.
- BF16 consistently outperforms FP8, maintaining lower loss values across all token ranges.
- **Inset Analysis** (zoomed region: 850–950 tokens/B):
- High-frequency oscillations in loss values (range: -0.001 to +0.001).
- Suggests numerical instability or quantization noise in this token range.
## Chart 2: BF16 vs FP8 on 230B DeepSeek-V2
- **Title**: "BF16 v.s. FP8 on 230B DeepSeek-V2"
- **X-axis**: "Tokens/B" (range: 0–800)
- **Y-axis**: "Loss" (range: 1.7–2.5)
- **Legend**:
- Blue line: BF16
- Orange line: FP8
- **Key Observations**:
- BF16 demonstrates significantly steeper loss reduction compared to FP8.
- FP8 exhibits a slower convergence rate, with loss values remaining higher throughout.
- **Inset Analysis** (zoomed region: 500–750 tokens/B):
- Similar oscillatory behavior observed in the 16B model, with loss fluctuations between -0.001 and +0.001.
- Indicates potential quantization artifacts in larger model configurations.
## Cross-Model Comparison
| Metric | 16B Model (Tokens/B) | 230B Model (Tokens/B) |
|-----------------------|----------------------|-----------------------|
| **BF16 Final Loss** | ~1.85 | ~1.75 |
| **FP8 Final Loss** | ~1.95 | ~1.85 |
| **Convergence Speed** | Moderate | Rapid |
## Technical Notes
1. **Loss Measurement**: Loss values represent validation loss during training, with lower values indicating better model performance.
2. **Quantization Impact**: BF16 (16-bit floating point) consistently outperforms FP8 (8-bit floating point) across both model sizes.
3. **Numerical Stability**: Oscillations in the 850–950 token range (16B) and 500–750 token range (230B) suggest potential precision limitations in FP8 quantization at higher token densities.
4. **Model Size Sensitivity**: The 230B model shows more pronounced performance differences between BF16 and FP8, indicating quantization effects scale with model complexity.